
Sanitized open-source datasets for natural language and code understanding: how we evaluated our 70B model
- Introduction
- What we are releasing
- Why we created and sanitized these datasets
- Why we selected these benchmarks
- Why we chose multiple-choice evaluations
- Why we sanitized public datasets
- Why we created private evaluation datasets
- Why we created our own CodeComprehension dataset
- How we identified and sanitized low-quality questions
- I. Collecting human-quality judgements
- II. Combining human judgements into a single quality metric
- Sanity-checking the combined human quality metric
- IV. Training the question quality detection model
- V. Cleaning up evaluation data: Identifying mislabeled examples
- Reflections and learnings
- Question quality predicts model performance
- How Imbue 70B compares to other frontier models
- Low-quality questions skew evaluations
- Conclusion
- References
This is the first of a three-part series on how we trained our 70B model. We covered setting up infrastructure, conducting evaluations, and hyperparameter optimization.
Introduction
When training our 70B model, we sought to accurately evaluate models for natural language understanding and reasoning abilities. To do so, we needed high-quality datasets on which to evaluate our models — free of confusingly worded, unclear, subjective, ambiguous, unanswerable, or mislabeled questions. Such questions can skew evaluation results: if a model “incorrectly” answers a highly ambiguous question, the issue would lie more with the question itself than with the model’s reasoning capabilities.
To address this, we sanitized 11 publicly available multiple-choice question-answering datasets and created private versions consisting of handwritten questions by human annotators. After removing low-quality and mislabeled questions, we found that all evaluated open-source and closed models — our 70B model, Llama 2 70B, Llama 3 70B, GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro — achieved high accuracy on both publicly available and private benchmarks.
Today, we are releasing the sanitized public datasets, our private datasets, a fine-tuned Llama 3 70B model to identify question quality, along with an entirely new dataset of questions related to reasoning about code. In this piece, we:
- Explain the datasets we’re releasing
- Detail our reasoning behind creating and sanitizing these datasets
- Outline our process for evaluating questions
- Share our findings from evaluating a variety of models on both the public and sanitized versions of each dataset
What we are releasing
As part of our 70B model toolkit, we are releasing a series of new and sanitized evaluation datasets to help robustly evaluate reasoning models. With these sanitized datasets, we were able to more accurately evaluate the performance of our 70B model against other frontier models.
These resources include:
- High-quality1 and correctly-labeled subsets of 11 academic reasoning benchmarks:
- Up to 1,000 items from the original dataset that have been screened for quality
- Up to 1,000 new human-written questions, so others can precisely evaluate their own models without fear of data contamination
- Tools for identifying and removing low-quality questions from an evaluation dataset:
- A dataset of 450,000 human judgments that our question quality model was trained on, so that others can investigate factors in human uncertainty about real-world questions or train their own question quality assessment models
- A fine-tuned 70B model, built with Meta Llama 3, to identify question quality in any evaluation dataset
- A completely new dataset about code understanding so that others can improve model performance on code-related reasoning
By releasing these tools and datasets, we hope to enable researchers to conduct accurate model evaluations and sanitize their own datasets to do so.
Why we created and sanitized these datasets
Why we selected these benchmarks
To evaluate our language model on natural language understanding and reasoning, we selected 11 benchmark datasets that fit a set of criteria. We rejected any benchmark dataset that was either:
- Too small to provide statistical power for comparing language model performance.
- Low-quality, meaning that from a manual exploration of a small number of examples, it was apparent that the dataset contains large amounts of low-quality or mislabeled examples.
- Optimized for capabilities other than reasoning. For example, we eliminated benchmarks like MMLU, for which performance relies to a large extent on memorization. We believe that the approach to solving memorization tasks involves developing tools that can find relevant information in real time, and the pre-trained language model itself should primarily be optimized for reasoning, not factual knowledge.
- Uncommon in other AI/ML research.
Given these specifications, we decided to use the following datasets: ANLI, ARC, BoolQ, ETHICS, GSM8K, HellaSwag, OpenBookQA, MultiRC, RACE, Social IQa, and WinoGrande.
Why we chose multiple-choice evaluations
Our goal was to assess the performance of our base language model, a single next-token predictor, without chain-of-thought reasoning or in-context learning. To evaluate this, we converted all evaluation questions to a multiple-choice format, using a simple prompt that asked the model to output single-token completions (e.g., “A”, “B”, “C”). For datasets without alternative incorrect answer options like GSM8K, we created sensible options via dataset-specific approaches.2 For datasets which contain a single passage of text with multiple questions (like RACE), we converted the dataset to a list of passage-question pairs.
Next, we standardized the model responses. To ensure that our model would always answer with a capital letter, we fine-tuned the model to follow a straightforward prompt (e.g., “Always answer A, B, or C”). We used CARBS, our hyperparameter optimizer, to determine the optimal parameters for instruction fine-tuning. For the open models we evaluated (Llama 2 70B and Llama 3 70B), we used the same prompt, procedure, and model-specific optimal hyperparameters as determined by CARBS. For the closed API-based models that were already fine-tuned internally (GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro), we engineered a prompt to ensure that these models would also answer the original question without additional reasoning traces or chain-of-thought. We scored all models on accuracy: the fraction of questions for which the highest-likelihood answer is correct.
Why we sanitized public datasets
The 11 public datasets we chose were not immediately usable, as all of them contained different amounts of low-quality questions: questions that were confusingly worded, unclear, subjective, ambiguous, unanswerable, or mislabeled.
An example of a low-quality question from the RACE dataset:
textFor this question, our model chose “Australian Eastern coastline”, which matched Llama 3 70B and all closed models we tested. The intended correct answer was “Koala Conservation Center”, which Llama 2 70B selected. However, this does not necessarily indicate Llama 2 70B’s superiority as a language model. Since the question itself is ambiguous — there are spelling and grammar errors, and the passage is completely irrelevant for the purpose of answering the question — whether or not a model answers “correctly” does not necessarily indicate reasoning abilities.
To identify low-quality questions, we hired human annotators to help manually evaluate data quality. This resulted in 450,000 human judgments, which we used to train a model for predicting low-quality questions. We detail the process of collecting human judgments in the “How we identified and sanitized low-quality questions” section below.
Why we created private evaluation datasets
To ensure that we could evaluate models without contamination, we also created private versions of each dataset with handwritten questions by human annotators, matching the style of the public versions as closely as possible. For reading comprehension datasets like BoolQ, RACE and HellaSwag, we provided passages of texts that annotators could write questions about. For science-based datasets like OpenBookQA and ARC, we provided a collection of science facts. We instructed human annotators to independently verify these facts, and in all cases, the questions and answers themselves were entirely human-written, guaranteeing no overlap or contamination with the training data. We employed multiple layers of quality assurance, including quality filtering, which we explain below. The final versions of these private datasets are available here.
Why we created our own CodeComprehension dataset
The goal of our pre-training effort was to build language models that can reason and write code. However, there were few existing benchmarks that help with evaluating whether or not our trained model contains representations that can support code generation. Most are either focused on specific tasks that are unrelated to reasoning (ex: search similarity), or are too difficult for a pretrained model to solve without explicit reasoning or chain-of-thought.
Therefore, we set out to create a new, high-quality dataset for reasoning about code. We have generated multiple such datasets and are releasing one of them today. This dataset contains code comprehension questions in which the language model has to predict the output of a procedurally generated code snippet. For example:

We ensured that examples are at a difficulty level easy enough for humans to identify the correct answer (in this case “-7”) if given access to a scratchpad. In all cases, the Python code runs and the correct answer is the actual output of the code. We selected alternative answers by introducing common mistakes in the execution trace of a code snippet. In the example above, the answer “-8” could result from incorrectly executing the conditional if w in '8':. Thus, we created a dataset of challenging questions with plausible alternative answers but a human accuracy close to 100%.
While high performance on this dataset does not guarantee that a model is able to generate correct Python code, it does indicate the presence of features that support code understanding, which are likely to also be conducive for generation. Moreover, while this dataset only tests procedurally generated code — which is relatively low-complexity and non-realistic — we are creating similar datasets with real-world code which are even more challenging. We are publicly releasing our CodeComprehension dataset, available here.
How we identified and sanitized low-quality questions
To identify low-quality questions, we trained a language model on human judgments about question quality from a seed set of putatively low-quality questions, distributed roughly equally across datasets (but excluding CodeComprehension and GSM8K). This involved collecting human quality judgments, combining them into a single quality score, then fine-tuning Llama 3 70B to predict the quality of a question. We detail the process below.
I. Collecting human-quality judgements
To assess question quality, we collected judgments from 10 vetted annotators for 1,000 questions.3 We sourced annotators through Prolific using a variety of quality assurance mechanisms:
- Setting the study eligibility to U.S.-based annotators who had previously completed at least 500 tasks with perfect approval rate
- Administering an instruction-understanding quiz
- Establishing automated detection and re-recruitment of outlier annotators using a set of golden questions
We ensured that annotators were fairly compensated and instantly approved all submissions, including those we did not ultimately use in the final dataset. In our released human annotation data, we replaced all participant IDs with random identifiers, ensuring anonymity.
For a given question, annotators indicated:
- What they think the correct answer to the question is
- Their confidence in that answer, on a scale from 1 to 10
- The extent to which each of the following reasons applies:
- “The passage contains spelling or grammar errors that make it harder to understand”
- “The question contains spelling or grammar errors that make it harder to understand”
- “Some of the answers contain spelling or grammar errors that make it harder to understand”
- “It is not clear what the question is trying to ask”
- “The question can be interpreted in multiple ways”
- “The question is subjective, asking for opinions rather than facts”
- “The passage does not provide enough information to answer the question”
- “The passage contains information that I know to be incorrect or it is self-contradictory”
- “Some of the answers don’t make sense given the question”
- “Identifying the correct answer requires additional context or assumptions”
- “The correct answer isn’t part of the presented options”
- “There are multiple answers that are potentially correct”
- “My own knowledge about this topic is too limited to understand the question”
For each reason, annotators chose between “Not at all”, “A little”, “A fair amount”, and “A lot”. These specific reasons are motivated by different quality issues we identified in manual exploration of the evaluation datasets. If a question passes all the checks (it is correctly spelled, clear, objective, there is only one correct answer, etc.), it is likely to provide reliable information about the capabilities of a language model.
II. Combining human judgements into a single quality metric
To train a language model on human-quality judgments, we found it useful to combine all human judgments into a single holistic-quality measure. Each question yielded 150 judgments total: every annotator provided one answer to the question, one confidence rating, and one response for the 13 potential reasons, for an individual total of 15 judgments per question, then multiplied across 10 annotators.
To calculate the single holistic quality measure, we combined three metrics:
- The average confidence of annotators in their answer
- The inter-annotator agreement, measured as the negative entropy of the distribution of answers across annotators
- The average score across all reasons and annotators, where the ratings are scored as 1 for “Not at all”, 2 for “A little”, 3 for “A fair amount”, and 4 for “A lot”
We determined the combination of these metrics using principal components analysis, which optimizes for extracting the common signal that is shared between the different metrics.
To show how the final combined metric corresponds to the individual components, we plotted the average confidence, entropy and score as a function of combined question quality, using 25 bins for ease of visualization.
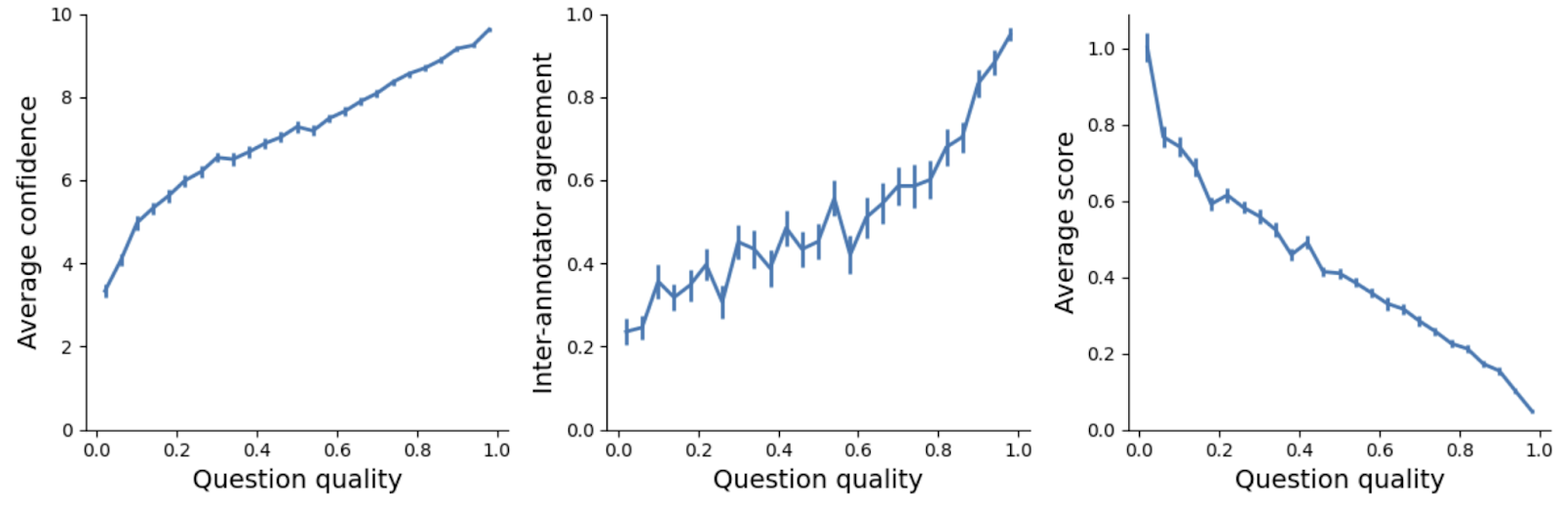
Sanity-checking the combined human quality metric
To illustrate the human quality data and verify that the combined metric indeed captures quality well, we’re sharing three question examples: the lowest-quality, the highest and a representative intermediate. For illustrative purposes, we selected these all from the OpenBookQA dataset.
The lowest-quality OpenBookQA question as rated by annotators is:
textOn this question, human annotators were divided equally between “keep your brain clean” and “should be ate when they are green”, responding with a mean confidence of only 1.7/10 for the following reasons:
- “The correct answer isn’t part of the presented options” (9 out of 10 annotators)
- “Identifying the correct answer requires additional context or assumptions” (9 out of 10 annotators)
- “Some of the answers don’t make sense given the question” (9 out of 10 annotators)
- “It is not clear what the question is trying to ask” (7 out of 10 annotators)
- “The passage does not provide enough information to answer the question” (6 out of 10 annotators)
The highest-quality example is:
textFor the above example, all 10 annotators answered “growth” with a confidence of 10/10, and not a single annotator reported any reason that would limit their confidence.
Finally, an intermediate question:
textIn this case, human annotators responded with a high average confidence of 9.5/10, but their answers were divided between “Buy supplies” (7 out of 10 annotators) and “Watch Tv” (3 out of 10 annotators).
Additionally, they reported multiple reasons that would limit their confidence:
- “There are multiple answers that are potentially correct” (5 annotators)
- “The question can be interpreted in multiple ways” (4 annotators)
- “The question is subjective, asking for opinions rather than facts” (3 annotators)
- “Some of the answers don’t make sense given the question” (3 annotators)
For this question, the different signals (confidence, disagreement, and reasons) somewhat conflict, resulting in an intermediate combined quality score.
Though the “highest-quality” questions still contained idiosyncrasies, the examples were generally ordered correctly, with the lowest-quality questions receiving the lowest mean confidence scores from annotators. These questions, which are of such low quality that even human annotators are uncertain, are therefore not informative as a test of language model reasoning capabilities.
IV. Training the question quality detection model
We fine-tuned Llama 3 70B on this data as a binary classification task between the top-half and bottom-half of questions by combined question quality score, with the prompt:
textOur resulting model achieved 61% accuracy on a held-out validation set after hyper-parameter tuning with CARBS. While this is not perfect, the fine-tuned model always responded with “yes” or “no”, and the probability P(“yes” | question) provided a graded quality metric. This metric correlated with the original human per-question quality score on the held-out set (Spearman’s ρ = 0.41, p<0.001). Going forward, we will categorize questions as high or low quality by applying thresholds to the P(“yes” | question).
V. Cleaning up evaluation data: Identifying mislabeled examples
Another problem with evaluation benchmarks is the existence of questions for which the intended “correct” answer was incorrect, also known as label noise. For example, consider this question from the BoolQ dataset:
textThe “correct” answer as indicated in the original dataset is “Yes,” but the majority response of our human annotators responded “No.” This matched our model’s answer, as well as that of GPT-4o, Claude 3.5 Sonnet and Gemini 1.5 Pro. Thus, the question is mislabeled.
In order to identify such examples in the test set, which was not annotated by humans, we investigated questions that a majority of the language models we tested answered “incorrectly”, and manually labeled them. Using this process, we identified 179 incorrectly labeled questions in the publicly available test data, and 80 in our private versions of the same datasets. In our evaluations, we used the corrected labels for these questions.
Reflections and learnings
Question quality predicts model performance
To validate our model of question quality, we investigated the performance of the language models on questions of different levels of quality. We expected that frontier language models should be able to answer them well, since high-quality questions are supposedly unambiguous, uniquely and clearly interpretable, free of spelling or grammar issues, and paired with intelligible answer options.
This is indeed what happened. In the figure below, we plotted accuracy for all models on questions in the RACE dataset, broken down by different levels of question quality. Note that the y-axis starts at 0.5 for visibility. All models achieved accuracy close to 100% for all high-quality questions. As the questions became lower in quality — they are more ambiguous, have either no correct answer or multiple correct answers, or are not clearly worded — the language models performed worse. Note, however, that even on low-quality questions, all models performed much better than chance, as even in the face of ambiguity, spelling or grammar issues, it was often possible to guess correctly at a higher rate than by random chance.
In our sanitized evaluation datasets, we removed all questions with a quality score below 0.15. This removed 4.2% from the public evaluation datasets, but only 3.0% from the private versions we created, which were judged to be of higher quality (0.684 ± 0.002 vs 0.511 ± 0.002, p < 0.001).
How Imbue 70B compares to other frontier models
Using our sanitized datasets based on the quality judgments we collected earlier, we evaluated our model alongside five frontier models. We compared our 70B model to Llama 2 70B and Llama 3 70B using publicly available model weights and code, as well as Claude 3.5 Sonnet, GPT-4o and Gemini 1.5 Pro, available through their respective APIs as of June 21, 2024. In our hands, GPT-4 Turbo and GPT-4 behaved similarly to GPT-4o, so we chose to display only one of them here. We emphasize that, because we evaluated all models zero-shot without chain-of-thought, these numbers do not reflect the best possible scores one can achieve on these datasets, but do reflect most faithful comparison to the fine-tuned 70B models, which also do not include chain-of-thought.
The graph below displays the accuracies of all six models on the sanitized test set of public evaluations, aggregated across the 11 datasets. Imbue 70B, Llama 2 70B, and Llama 3 70B are fine-tuned to minimize the weighted aggregate cross-entropy across these 11 datasets. Note that the y-axis starts at 0.5 for visibility. Error bars indicate standard error of the mean across questions.
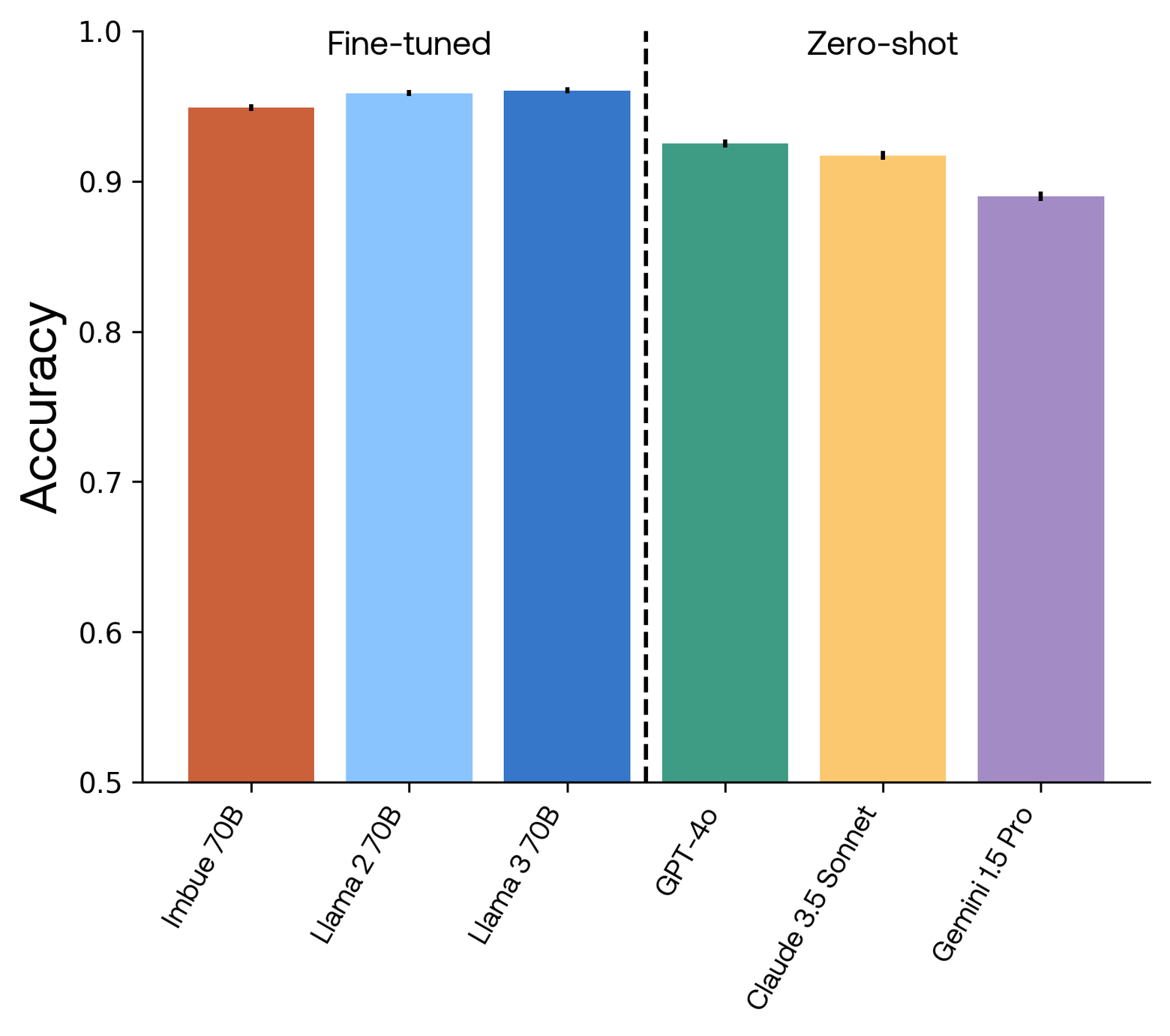
Evaluated on 11 publicly available datasets, our model performed comparably to Llama 2 70B and Llama 3 70B, and outperformed the zero-shot GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro.
Our results are not cherry-picked: we ran only one pre-training run, we ran CARBS only once to fine-tune our model to follow prompt answering instructions, and we independently executed the same procedure for Llama 2 70B and Llama 3 70B. We show performance on a test set that was not involved in hyperparameter optimization, and have removed any duplicates between the test, train and validation datasets. Therefore, the results presented here reflect an unbiased picture of the expected performance when pre-training your own 70B model, as long as your pre-training data is of similar quality as ours.
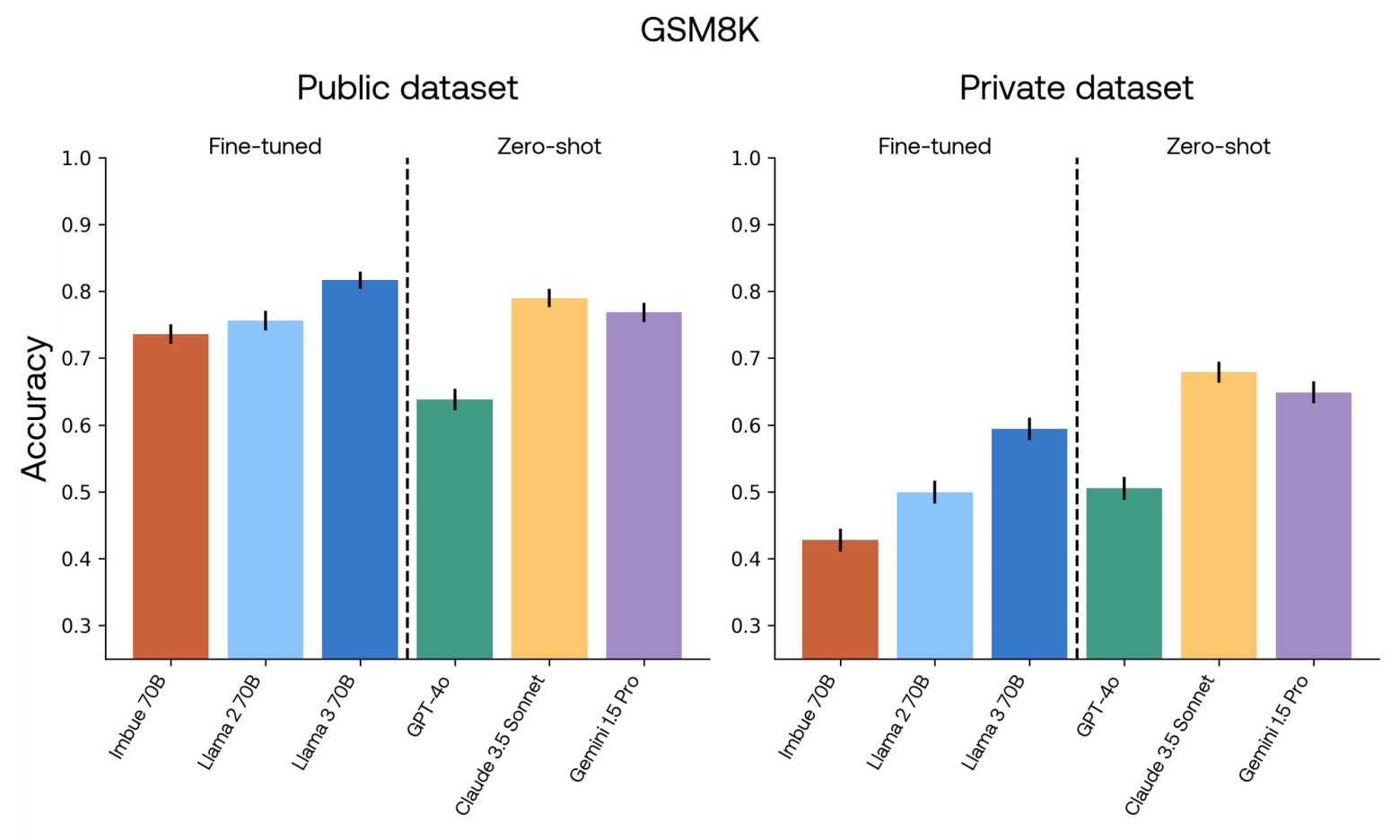
We also evaluated the performance of each model on the private evaluation datasets we created. Here we show the performance of all models on both the public and private versions of each dataset. Note that for GSM8K, the y-axis starts at 0.25.
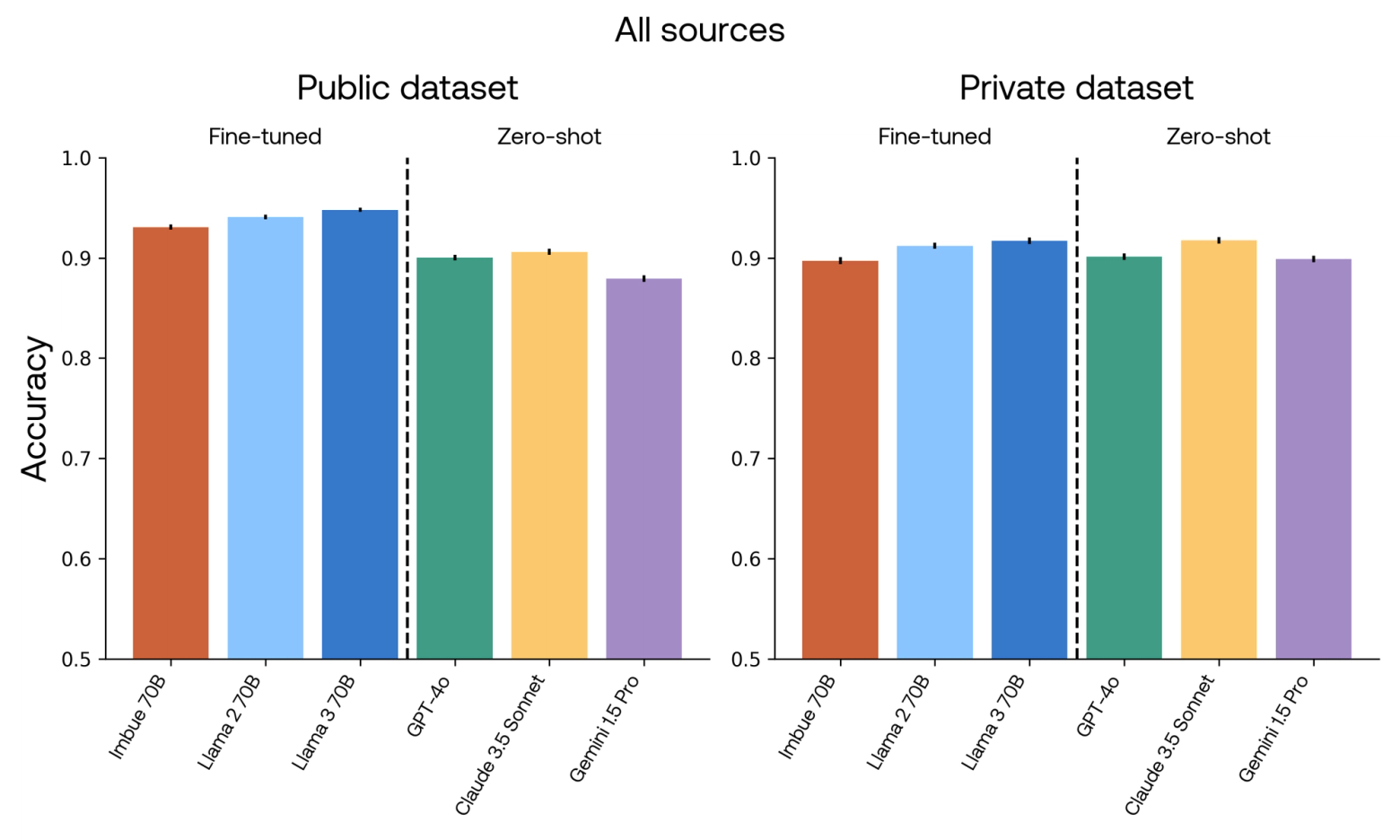
To contextualize these results, it’s worth looking at individual datasets. Our model most outperformed GPT-4o on datasets such as ANLI and ETHICS, which involve decisions with subjective boundaries such as “is this scenario acceptable from an ethical standpoint?”, or “does this passage contain enough information to answer this question?” Because our model was fine-tuned, it could learn these boundaries, whereas this was much more difficult to achieve by prompt-tuning a zero-shot closed language model. This was most apparent for Gemini 1.5 Pro on the ETHICS dataset. With our prompts, Gemini 1.5 Pro identified approximately 65% of scenarios as unethical. This was mostly due to bias, since the original dataset is approximately balanced, and only 43% of scenarios are labeled as unethical. This bias explained almost all errors made by Gemini.
On the other hand, one dataset where GPT-4o outperformed our model was ARC, which consists of knowledge-based scientific questions. Since GPT-4o was trained on much more data than our model, it has likely encountered more science facts and its superior performance reflected its ability to memorize those facts.
Finally, in this evaluation, GPT-4o performed poorly on GSM8K, a mathematical reasoning dataset. This was due to our requirement for models to output the answer without any chain-of-thought, which made the task much harder. Also note that our private version of GSM8K is a more difficult dataset (both in terms of the content of the questions, and in that there are four alternatives instead of three), which accounts for the lower performance across all models.
The model comparison results on the private datasets we created to mimic the public ones were largely similar, with two notable exceptions: MultiRC and HellaSwag.
For these datasets, there was a large shift in the distribution of questions and passages. HellaSwag sourced passages from WikiHow.com, which represent a distinctive style and range of topics. On the other hand, in our private version of this dataset, we sourced passages from a much broader web scrape. For the models that were fine-tuned on the public datasets, this implied a distributional shift, which decreased performance. Similarly, MultiRC is unique in that questions can have up to 12 candidate answers, of which multiple can be correct. In our private version, the number of candidates and number of correct answers are both restricted, which also caused a shift.
Low-quality questions skew evaluations
Because low-quality questions were responsible for a significant portion of the differences in model performance, we found that it was critical to ensure that we used high-quality questions to ensure that our results accurately reflected the models’ capabilities. Even with publicly-released datasets, there were a notable amount of low-quality questions, enough to significantly skew evaluation results.
For multiple datasets, all open-source and closed models we evaluated — Llama 2 70B, Llama 3 70B, Claude 3.5 Sonnet, GPT-4o, Gemini 1.5 Pro, and our own — achieved near-perfect accuracy on unambiguous questions, aside from questions that were mislabeled. Thus, model performance on these datasets primarily captured how well a model matched idiosyncratic human answers to low-quality questions — which is an interesting topic, but does not necessarily measure model reasoning capabilities.
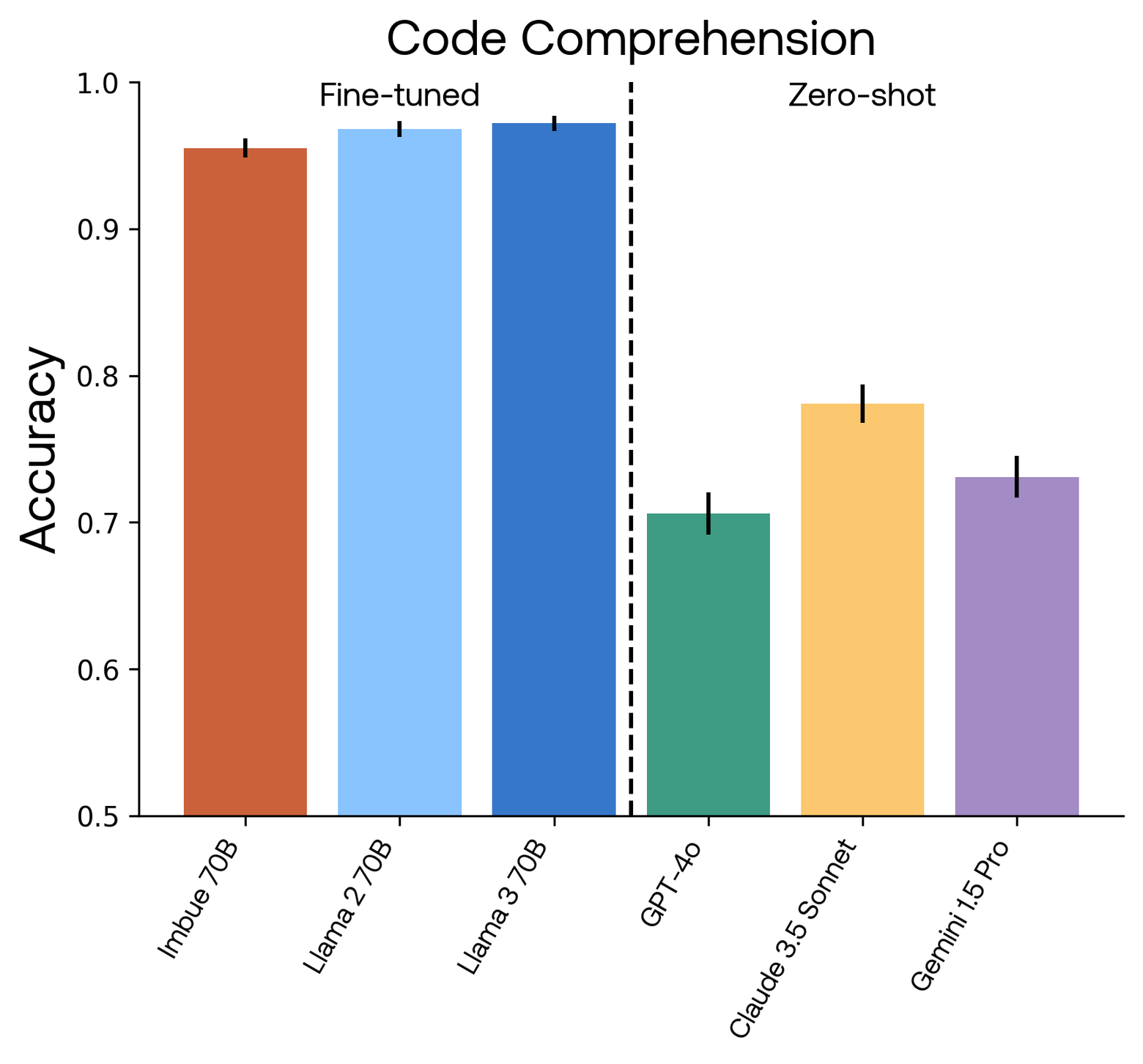
Finally, we evaluate our model and all alternatives on the Code Comprehension dataset we created. This dataset is challenging, and the closed models (GPT-4o, Claude 3.5 Sonnet and Gemini 1.5 Pro) scored around 70-75% accuracy. However, fine-tuning allows our Imbue 70B and the two Llama variants to perform close to perfectly on this dataset. This underscores the power of fine-tuning: even though our procedural generation contains enough variation that the train and test set contain no exact duplicates, the fine-tuned models are able to capture the idiosyncratic structure inherent in these examples and the procedural generation pipeline. While this particular dataset is close to solved by fine-tuning, this is largely due to our restriction that the questions be relatively easy for a person to answer quickly, and because the dataset is meant to be used without chain of thought reasoning. This style of question can be extended to be arbitrarily complex, and represents an interesting domain in which to explore more complex reasoning.
Conclusion
By digging into these evaluation questions, we learned that existing datasets primarily optimize for performance on low-quality questions. After controlling for question quality — both by creating our own versions of the datasets and by using the fine-tuned Llama 3 70B model to remove low-quality questions — we can see that many of these benchmarks are largely solved by today’s frontier models, including our own pretrained 70B model. Partially motivated by this, we have created our own internal evaluations, such as the CodeComprehension dataset for reasoning about code, to better measure progress on training models that can reason and code.
We hope that the resources we’ve released — the cleaned-up test sets from public benchmarks and private recreations of those same benchmarks, along with the 450,000 human labels about question quality — will aid researchers in evaluating their own models’ reasoning performance and exploring questions around identifying ambiguity and other sources of low-quality data. We’re encouraged by the ability to achieve state-of-the-art results with open-source and custom-trained models after fine-tuning, especially for tasks with predictable formats and subjective criteria.
By sharing these tools and datasets, together with our infrastructure scripts and hyperparameter optimizer, we aim to make it faster and easier for teams of all sizes to train powerful models tailored to their goals.
References
- Questions which have no correct answer, are subjective, incomprehensible, etc. See the section, “Why we sanitized public datasets,” for more information. ↩
- For example, for GSM8K, we examined the most likely wrong answers and the results of applying the wrong operations or wrong order of operations to the quantities in question. ↩
- We also collected judgments for 1,000 pseudo-randomly selected OpenBookQA and 1,000 BoolQ questions. We do not analyze those judgments here, but you can find them at the above links. ↩