
Training a 70B model from scratch: open-source tools, evaluation datasets, and learnings
- Introduction
- 1. Sanitized open-source datasets for natural language and code understanding: how we evaluated our 70B model
- 2. From bare metal to high-performance training: Infrastructure scripts and best practices
- 3. Open-sourcing CARBS: how we used our hyperparameter optimizer to scale up to a 70B-parameter language model
- Takeaways
Introduction
Earlier this year, we pre-trained a 70B-parameter model and fine-tuned it on a range of multiple-choice reasoning benchmarks. On these benchmarks, our fine-tuned model outperforms GPT-4o zero-shot (which was not tuned on these benchmarks). Our fine-tuned model, pre-trained on 2T tokens, also approaches the performance of fine-tuned Llama 3 70B, which was pre-trained on more than seven times as much data.
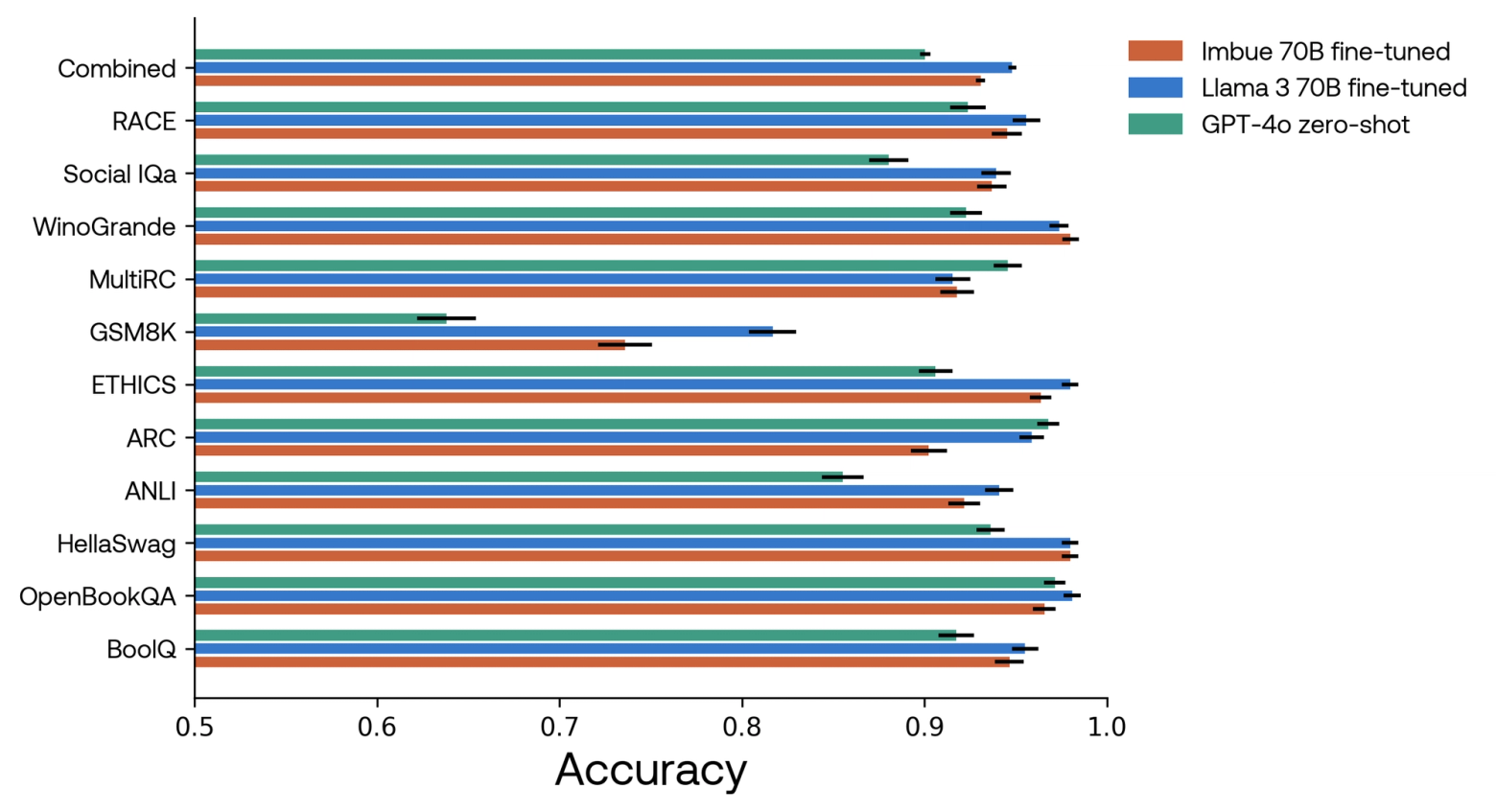
Because we evaluated GPT-4o zero-shot without chain-of-thought, its performance above does not reflect the best possible scores it can achieve on these datasets. However, this is the most faithful comparison to the fine-tuned 70B model evaluations, which also do not include chain-of-thought.
Using our hyperparameter optimizer, CARBS, we scaled this system up to 70B parameters on our first attempt with minimal training instability and no loss spikes. This involved training thousands of dense transformer models with group query attention, SwiGLU activations, RMS normalization, and a custom tokenizer at a range of smaller sizes.
To help other teams train, scale, and evaluate models tailored to their own research and product goals, we’re releasing the tools that facilitated this work. The toolkit includes:
- Cleaned-up and extended versions of 11 of the most popular NLP reasoning benchmarks
- CodeComprehension: an entirely new code-focused reasoning benchmark that stumps current-day frontier models
- A fine-tuned 70B model, built with Meta Llama 3, to measure question quality
- A new dataset of 450,000 human judgments about question quality
- Infrastructure scripts for bringing a cluster from bare metal to robust, high performance training
- Our cost-aware hyperparameter optimizer, CARBS, which automatically and systematically fine-tunes all hyperparameters to derive optimum performance for models of any size
For all of the above tools, we expanded upon our process for creating and utilizing them in the following blog posts:
1. Sanitized open-source datasets for natural language and code understanding: how we evaluated our 70B model
We are sharing datasets for model evaluation, consisting of high-quality subsets of 11 public datasets, and a set of original questions for code comprehension. We found that both open-source and closed models achieved nearly 100% accuracy on some datasets when evaluated only on high-quality, unambiguous questions. For more on why we selected these particular datasets, as well as details about the process of creating the data and the actual datasets themselves, see our detailed write-up on evaluations.
2. From bare metal to high-performance training: Infrastructure scripts and best practices
These scripts are a critical (and often undisclosed) piece of training very large language models. We hope that our efforts will make it easier for others to experiment at larger scales without needing to reproduce this infrastructure code and knowledge. For more details, see our write-up of our training process and infrastructure bring-up.
3. Open-sourcing CARBS: how we used our hyperparameter optimizer to scale up to a 70B-parameter language model
CARBS allowed us to scale to our large training run with minimal training instability and loss spikes on the first attempt — eliminating a huge source of risk for smaller teams experimenting with novel model architectures. We published an extended write-up on how we used CARBS to scale up to our 70B model.
Takeaways
We trained our model from scratch as an experiment to help answer a few critical questions:
- At a practical level, what does it take to build a proof of concept for technically robust agents that can reliably write and correctly implement robust, extensible code?
- What kinds of performance improvements can pre-training provide (vs. fine-tuning, reinforcement learning, and other post-training techniques)?
- What contributions do engineering optimizations in infrastructure, hardware, data, and evaluations contribute to building a robust and correct model?
Some key learnings from this experience:
- Clean evaluation datasets are key to properly assessing model accuracy. Identifying ambiguity and refining task specifications help build the critical foundations for building coding agents and other tools that can reliably take actions in the real world.
- Automated processes to diagnose and fix infrastructure problems are critical for efficient training, cluster utilization, and maximizing model performance.
- It is possible to run resource-efficient pre-training experiments that can effectively scale to a large model. Using CARBS, we could reliably predict the performance of any model with a given number of parameters according to well-defined scaling laws, lowering the barrier to entry to building large models.
This model training — including all of the above work on infrastructure, evaluations, and hyperparameter optimization — was completed by about a dozen of our engineers and researchers. It is one of many projects we are working on at Imbue. Our other focus areas include reinforcement learning, agent and reasoning architectures, data generation techniques, and experience design to make these powerful capabilities accessible and intuitive to users.