
Methodology for analyzing the individual comments to the NTIA’s AI RFC
- Methodology
- Validation
- Experimentation
- Initial exploration
- Filtering the dataset
- Deciding on the exact questions
- Collecting human data
- Improving LLM performance for accurate responses
- Alternative approaches we tried
- Limitations
- Limitations of the analysis
- Limitations of our methodology
- Conclusions
- Appendix
- Appendix A: human study design considerations
- Appendix B: instructions given to human participants
- References
Summary: This article describes the methodology and motivation for the analysis decisions of our investigation of the individual submissions to the NTIA’s AI Accountability Request for Comment. For our discussion of results and implications for policy makers, please see here.
Specifically, this report describes how we created the system to perform this analysis and how we validated its results. Throughout this exercise, we also critiqued our own work and investigated the limitations of what we ultimately produced. We hope that by communicating both the strengths and weaknesses of our system, this will result in greater confidence in how our system actually behaves and contextualize our conclusions about people’s concerns regarding AI Accountability. We believe this transparency is important when evaluating systems and it’s one piece of the puzzle to building safer AI systems.
We’ve uploaded our code to compute the results here.
We believe that, when using complicated AI systems to analyze data, those presenting an analysis ought to be responsible for also presenting sufficient data about their methodology that enables the reader to verify the results. In particular, this means providing not only the raw data, but the justifications of the various decisions made, as well as the procedures and methodologies that were used.
Here, we present what we believe represents a positive example of using large language models (LLMs) to analyze a relatively large and unstructured dataset – the set of all individual submissions [1] to the NTIA request for comment on AI accountability.
We had two goals for this project:
- Object-level goal: understand, in a quantitative sense, what worries people about AI by analyzing the responses to the RFC.
- Meta-level goal: understand, from a practical perspective, how to effectively use publicly accessible LLMs to answer questions about an unstructured data set.
The focus of this report is on the second (meta-level) question – how can we use these powerful models in order to create an analysis that we can actually trust? For more on the first question (what was actually said in the report), see our other post here.
The rest of this document is broken down as follows:
- In Methodology, we present the process used to collect data from LLMs on the final set of questions on which we settled.
- In Validation, we describe the way in which we collected data from humans about those same questions in order to validate that the results seem trustworthy.
- In Experimentation, we justify the decisions in our methodology and validation, including a number of alternatives that we explored while developing them.
- In Limitations, we review some of the limitations of both our analysis, at the object level, as well as our approach in general.
- In Conclusions, we give a brief summary and some recommendations for future work.
Methodology
We selected the following 15 questions after several rounds of iteration as we felt that in their entirety they would cover a majority of concerns within the submissions:
- Does the author state they are an artist, writer, or work in a creative field?
- Does the author state that they are a programmer, developer, or have similar software engineering experience?
- Does the author describe a personal harm they have experienced from AI?
- Does the author describe harm to a specific group of people?
- Does the author express concern about economic impacts, such as job loss, loss of income or financial hardship?
- Does the author express concern that AI systems will behave out of control?
- Does the author express concern about bias and discrimination, such as AI bias against minorities, inequality caused by AI?
- Does the author express concern about loss of privacy?
- Does the author express concern about cyberterrorism, national security, or risks from other countries?
- Does the author express concern about copyright infringement or intellectual property?
- Does the author express concern about the spread of misinformation by AI?
- Does the author express concern about deepfakes, impersonation, falsified content, or nonconsensual imagery?
- Does the author express concern about AI systems being used to manipulate humans or AI lacking human values?
- Does the author call for regulation of AI?
- Does the author express concern that properly regulating AI is difficult?
We attempted to answer these questions for every individual (non-corporate/non-entity) submission to the RFC that was:
- Written in English (excluded 3).
- Not a duplicate (excluded 14)
- Not consisting only of image attachments (excluded 2)
- Longer than 75 characters (excluded 30)
- Shorter than 20,000 characters (excluded 15)
This resulted in a final dataset of 1,198 assessed submissions. For each valid submission, we answered each of the 15 questions by querying GPT-4 with the following prompt:
textWe used a temperature of 0.2, and made at least 3 queries, taking the most common answer as the actual answer.
Validation
We validated our results by creating a “gold” set of labels by answering each of the 15 questions for 18 hand-selected submissions. We selected these submissions for diversity, and ensured that even for the most-skewed questions, we had at least some examples of both positive and negative answers. We selected 18 submissions as a compromise between the cost of doing additional submissions and the need to have a sufficiently large and diverse sample to get meaningful results.
In addition to the responses from GPT-4, we used the crowd sourcing platform Prolific to collect a large amount of responses from human participants as well. In total we recruited 406 participants, each of whom answered questions about 6 submissions: 1 taken from the gold set and 5 others. Participants were allowed to participate in multiple surveys on different sets of submissions; the most involved participant completed 11 such surveys. We excluded submissions longer than 2,000 characters from human labeling to avoid having to force people to read extremely long documents. In total, human participants rated 929 unique submissions. We took several steps to ensure we conducted our human data labeling in a fair and ethical manner, see Appendix A for details.
We performed quality assurance on the human responses at multiple overlapping levels:
- We included a basic eligibility filter, recruiting only participants who reside in the US, have US nationality, are 18 years or older, are proficient in English and have previously completed at least 500 studies with a 100% approval rating. Though this may seem strict, over 11,000 participants meet these eligibility criteria.
- We included a simple instruction-understanding quiz after explaining the task instructions, encouraging participants to re-read the instructions if they failed to answer all quiz questions correctly.
- If a participant’s answers on the one golden submission they read deviated too much from the golden answers, we excluded their data, and rendered them ineligible for participation in future surveys. However, this did not affect payment nor did these count as “rejections” on the Prolific platform.
- As an additional level of quality control, we had each batch of 6 submissions labeled by 3 different participants, and again excluded data from participants who deviated substantially from the modal response. For participants whose data was excluded in either of these steps, we re-recruited additional participants to fill the slot.
In practice, we found that all these steps contributed to increasing the quality of the human labeling data, and our final dataset contains a high level of agreement among participants, with a high level of confidence – the most common answer to any question about any submission was “Unsure” only around 1% of the time. The final instructions given to participants can be seen in Appendix B.
Our final results on our gold set are presented below in Table 1. For each question, we present 3 metrics of reliability:
- Agreement: the percentage of golden submissions for which the most common answer among human participants or the LLM matches the golden answer.
- Number of false positives: the number of golden submissions where the golden answer is “No” but the most common answer among human participants or the LLM is “Yes”.
- Number of false negatives: the number of golden submissions where the golden answer is “Yes” but the most common answer among human participants or the LLM is “No”.
Additionally, we present the same metrics for the LLMs, using the most common answer across 3 independent LLM runs as the modal LLM answer.
Table 1: Comparing Prolific Participants and LLMs on the Gold Set (higher agreement is better, lower false positives and false negatives are better).
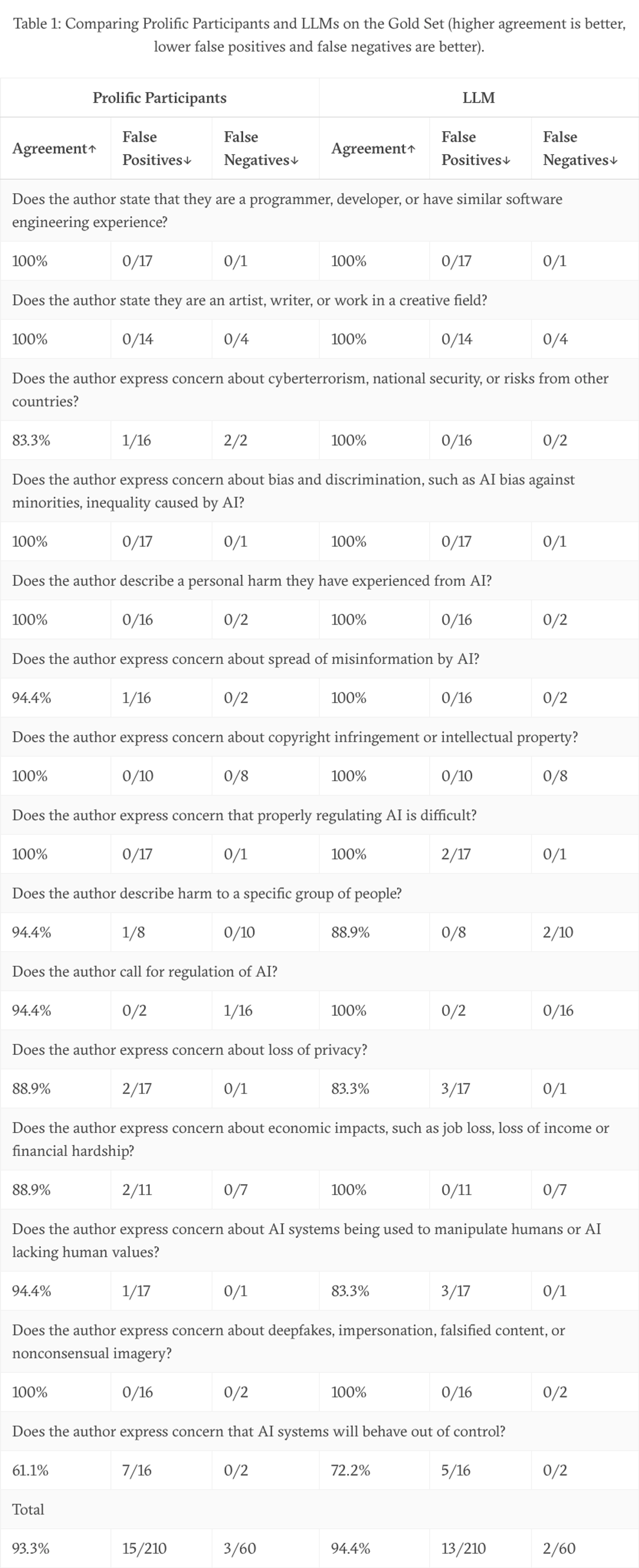
This data allows us to draw two conclusions:
- The LLM is slightly closer to the golden answer than human survey participants although the difference is small and not necessarily statistically significant.
- Both human participants and LLMs are biased and make more false positive errors (reporting that the author of a submission is concerned when they are not) than false negatives.
We also observe that the reliability of both human and LLM answers varies strongly between questions. To reinforce this finding, we also report two metrics computed across all submissions, golden or otherwise (see Table 2 below):
- The average agreement between any individual Prolific participant and the most common answer across participants.
- The percentage of submissions for which the most common Prolific participant response is “Unsure”.
These metrics too vary consistently across questions. The two questions asking about whether a commenter is an artist or software developer are the most reliably answered, while the questions asking for concerns about AI lacking human values or behaving out of control are the least reliable
Table 2: Prolific Participants internal agreement on questions.

Overall, the high agreement between our gold label set, the scores made by other human participants, and the LLMs, gave us enough confidence in our methodology to feel comfortable presenting them in our post summarizing our takeaways from analyzing the NTIA RFC dataset.
Experimentation
Our process did not begin with any of the details described above in the sections about questions, methodology, and validation. Rather, they each evolved over time as we iterated towards creating a set of results in which we had sufficient confidence to feel comfortable sharing more broadly.
Initial exploration
We started the process by exploring what was possible.
We created an initial question list, evaluation set, and the LLM infrastructure to ask our questions across all submissions. Through this exercise we started to better understand what questions we should ask. We also realized a need to look closely at the data, the importance of having a representative evaluation set, and the need for human labeling to help scale up the creation of this evaluation. This process gave us a rough outline of all the experiments that we felt were worth running on our system to see how far we could push performance.
Filtering the dataset
After this initial exploratory work, our next step was to better understand how exactly we should handle particular intricacies of the dataset and which submissions we could not analyze. In particular, we elected to filter out submissions that did not match our criteria above (too short, too long, non-English, etc) which reflect fundamental limitations of our approach based on LLMs and human labeling. Because the large majority (95%) of submissions passed these filters, we were able to manually review the remainder to ensure that their exclusion did not substantially affect the final conclusions. This work also allowed us to notice issues like duplicate submissions or submissions that contained attachments, which we handled by adding the text of each attachment to the submission.
Deciding on the exact questions
Much of our work and experimentation was around selecting the questions themselves. Through our own internal preliminary investigation of the questions, we removed any questions where the answer was subjective or the wording of the question itself led to ambiguity. We found that even short answer or non-binary multiple choice questions led to disagreement among humans, enough so that we struggled to build enough confidence in the LLM responses.
We developed the questions and the golden set iteratively, using a combination of human labellers, language models, and our own judgements.
We started with a list of questions based on our own hypotheses for what individuals who submitted to the RFC may be concerned about. For example, one such question was “Does the author express concern about loss of privacy or misuse of personal or restricted data?”
We then labeled each submission with yes/no answers using a language model, and selected the set of 18 golden submissions which we sampled pseudorandomly with the constraint that, for each question, there was at least one golden submission for which the LLM answered “yes” to that question, and one submission for which it answered “no”. We also ensured that a variety of submission lengths were represented.
Next, we recruited human participants on Prolific to answer each question for each submission, using 10-fold recruitment to assess consensus among participants. We also answered these questions ourselves, as did other members on our team. We presented questions to humans as multiple-choice between “Yes”, “No” and “Unsure”.
We removed, edited, or rewrote any questions for which the majority answer was “Unsure”, or for which participants did not exhibit a consensus on all golden submissions. We iterated this procedure until all questions were answered unambiguously by human participants in our golden submission set. For example, our final version of the above question now reads: “Does the author express concern about loss of privacy?”
Through this iterative procedure, we were able to arrive at a set of questions that was sufficiently unambiguous to function as an objective “gold” data set. This is what allowed us to benchmark both the LLMs as well as future human participants against a set of data that we could actually trust was correct.
Collecting human data
We iteratively developed each of the quality assurance datasets as we began collecting small scale versions of our human label data. For example, in one of the first runs, we noticed that there was a large variability in how long participants took to read submissions and answer questions. This led us to explicitly instruct participants about how much time they should spend reading, which largely alleviated the issue. We got a lot of value from being able to quickly run small-scale studies to test and refine our methodology, and ran about ~10 studies over the course of the project.
We also introduced two extra questions to help us identify any concerns we may have missed and to perform sentiment analysis in which our LLM struggled with in our early experiments. Extra questions provided to human labellers:
- Does the author raise any additional concerns about AI that were not covered by these questions?
- Is the author optimistic about AI? Answer between 1-5.
Improving LLM performance for accurate responses
Throughout the project, we constantly experimented with various prompts and methods of eliciting answers from the LLMs for all the questions we considered running. We often evaluated their performance on a small number of examples by hand when iterating, and on a larger number of examples as we started developing the ground truth and other human data.
We conducted our LLM experiments with off-the-shelf language models, specifically OpenAI’s GPT-4 and Anthropic’s Claude-2, so that our experiments and results could be replicated by others. As a first step, we iterated on simple prompting strategies until we felt confident the model was answering approximately correctly. This process consisted of two steps:
Given a prompt, we identified all golden submissions and questions where the LLM deviated from the golden answer. For each incorrectly answered question, we visualized the submission, prompts, and answers. We manually investigated this information to identify weaknesses in our prompting strategy and edited the prompt accordingly.
The prompt presented in the Methodology section is the one we settled on after this exploratory process. In particular, the final paragraph instructing the model to provide its answer between [answer] and [/answer] tags is helpful for ensuring that Claude-2 actually outputs the answer in the correct format.
Once we settled on a preliminary prompt and final golden evaluation set, we were then free to iterate on our system and experiment with alternatives that could boost agreement between LLMs and golden answers. Concretely, our quantitative metric was percentage of golden questions and submission for which the LLM’s output matched the golden answer, which we call the LLM-gold agreement. We also broke down any mismatches into false positives and false negatives, to assess any response bias in the models.
Additionally, we ran experiments where we changed LLM inference parameters to determine how to maximize the gold agreement. The specific parameters we tested were:
- The specific model being prompted (either Claude-2 or GPT-4).
- The temperature of the model.
- The number of samples (recall that we use the most common output across samples as the LLM answer).
- The prompting strategy (elaborated on in the next paragraph).
We found that, for both Claude-2 and GPT-4, results improved when we used a temperature of 0.2 and generated at least 3 samples. Although we could generate more samples, this would make the prompting process more expensive and time-consuming. We also found GPT-4 to perform superior to Claude-2 in our use case. Finally, we experimented with the following three prompting strategies:
- Simply provide an answer to the question (i.e, the prompt shown above).
- Reason about the question and then provide an answer.
- Reason about the question, reflect on the reasoning and critique it, and then provide an updated answer.
Surprisingly, the simplest strategy matched or outperformed these more complicated prompting strategies on our evaluation set. We observed some behaviors that may serve to explain why this happened:
- The model would tend to confuse or trick itself in the reasoning step, providing evidence for its answer that was not present in the original submission at all. This led to a proliferation of false positive errors, inferring that authors were concerned about issues they did not mention in their submissions.
- This issue motivated our choice to experiment with the reflect-and-critique stage, allowing the model to correct its own hallucinations. However, this tended to bias models to become less confident, leading to a sharp increase in the “Unsure” choice.
- For some questions, the reasoning step helped the model with our first iteration of questions, but as we refined these questions, removed ambiguity and iterated on our LLM prompt, this technique tended to hinder rather than help performance.
- Near the final stages of our iterative question refinement process, the LLM gold agreement started to reach a ceiling, and even the baseline LLM without any reasoning answered almost all questions correctly. At this stage, further experimentation would require an expanded evaluation set, so that we can identify and eliminate any failure modes of the baseline prompt-based system.
Alternative approaches we tried
Early on, we tried to investigate RFC submissions by asking language models to summarize their content. While this worked to some extent, we found that summaries often hid important content and did not accurately reflect the original commenter’s concerns. We eventually abandoned this approach in favor of our final question-based approach.
We also tried encouraging language models to give responses with an indicator of confidence by asking them to report answers on a 5-point scale. However, this data was unreliable, and calibrating scales between questions ended up being complicated (what does it mean to have “some concern”?). Therefore, we abandoned the 5-point scale and turned to a yes/no answer for all questions except for “Does the author feel optimistic about AI?” which was only answered by human labellers.
Similarly, we had trouble processing the model’s responses to open-ended questions, such as “What does the author do for a living?” Instead, we converted these questions to a yes/no format, replacing them with specific questions asking if the author was an artist or if they were a software engineer.
Finally, we learned that formulating questions in great detail tends to confuse both language models and human labellers. This led us to simplify our questions over time - for example, we decided to ask for concerns about “privacy” instead of “privacy and misuse of personal or restricted data”.
Limitations
While we have tried to be as thorough as reasonably possible with this analysis, there remain many limitations at both the object level (e.g., what we can conclude about people’s concerns about AI) as well as at the meta level (e.g., how confident we can be in our conclusions).
Limitations of the analysis
In our view, the primary limitations of the analysis itself are as follows.
- A heavily biased, limited sample of respondents. Given the fact that this data was collected in response to a request for comments (that most people probably didn’t hear about or did not have the time or expertise to craft a response, especially those people who are most likely to be disadvantaged by AI in the future), there is simply no way we can make statements about how the general public of the US feels about the risks of AI. At best, we can make statements about the fraction of respondents who feel a particular way, and we can make claims about existence (eg, “at least some people feel X”). This is an obvious but very limiting cap on the power of any claims that can come from analyzing this dataset.
- The limited format of a request for comment. We can only really answer questions that are explicitly addressed in the comments themselves, and have no ability to interact with the individuals who created those submissions. We cannot ask follow up questions, nor can we ask questions about topics that such individuals likely do care deeply about, but found perhaps too obvious to write about.
- The limited knowledge of the respondents. If our true objective is to actually regulate, we want to know what the real risks and future harms and dangers of AI are. There is no guarantee that asking random individuals will give us very good coverage on those questions.
- The inherent limits of summarizing data. Any analysis that is shorter than the original dataset must have thrown away some of the data, and depending on what that data is, we could easily be losing some very interesting and valuable insights. It’s entirely possible that a handful of submissions were incredibly insightful, and this type of analysis will not find those comments. It should certainly be coupled with a more qualitative exploration of the data, looking for unique, diverse, and high quality submissions to read directly.
These limitations are extremely serious. One should not construe our analysis as saying something about the broader questions about AI risks, dangers, and harms because the underlying dataset simply does allow such broad statements.
This is a major part of the reason why we are focused on the methodology — in a sense, the way in which we have answered these questions is somewhat more interesting than the questions or answers themselves.
Limitations of our methodology
At the object level, our analysis suffers from additional limitations: did we ask the right questions? Did we phrase them correctly? Do those questions cover the issues that were actually raised in the responses? Are the questions sufficiently unambiguous? Even taking as fixed the questions we ultimately decided to ask, there are also limitations in how confident we can even be in our answers to those questions.
However, unlike the limitations on our analysis, the limitations on the methodology are somewhat less serious. However, there are factors that could have introduced noise or error into our answers:
- Our questions, models, and humans are each biased in their own way. There may be bias from the selection of our participants on Prolific, as well as those on our team who made the gold label dataset. This is likely a relatively small source of error given the high agreement yet diverse demographics between those two populations, and given that the actual questions skew towards the relatively objective, but it is important to consider when doing any such study. There may also be bias inherent in the questions themselves. There is certainly some bias in the way in which the language models answer the questions as well. The final iteration of our language model results is biased toward reporting false positives. In our results, we show that the LLM has a consistent tendency to the errors it makes, in that when asked “Does the author raise concerns about X”, language models are biased towards saying that indeed, the author is concerned about X. Notably, though, in earlier versions with different prompts or a different LLM, we also observed the opposite bias. Without transparency in how exactly these models are trained, fine-tuned, and deployed, it is not possible to pinpoint or control the source of this bias.
- We cannot ask the exact same questions to human labelers and language models. As we show above, the LLM prompt contains additional instructions that human participants did not see; similarly, participants saw instructions that didn’t apply to the LLM (for example having to do with the task duration and payment). Thus, while we present conceptually the same questions, exact matching is impossible.
- Some questions may not be possible to convert to a binary yes/no answer. As part of our analysis, we phrase all questions as multiple-choice questions between “Yes”, “No” and “Unsure”. While this is convenient from an analysis perspective, it may pose limitations on the types of questions we can even ask.
- Some responses had to be filtered out in order to make analysis practical. As mentioned above, submissions which were too short or too long had to be filtered out for practical reasons in order to make it possible to ask questions that actually made sense. We also could not address comments that were not in English. These filters introduce a particularly pernicious form of bias, and are worth considering in future (higher stakes) projects.
- Our metrics may be missing important nuances. While we tried to present a variety of different metrics for analyzing agreement (including both the false positives and false negatives separately, for example), it is possible that our aggregate metrics are hiding some important sense of systematic error. For example, it is entirely possible that the language model could be particularly bad at answering a particular type of question, but that this only happens when the submission is formatted in some particular way. We don’t believe this is a significant source of error for this dataset and these questions, but it is an important source of error to consider when using this approach.
- We had a limited amount of time and money to spend. This type of analysis is expensive and time consuming. Throughout all our analyses, we spent around $4,000 on human labeling and a comparable amount on API fees for language models. Additionally, conducting this analysis required engineering effort in setting up our tools, and as a team we went through many cycles of collecting data, analyzing it, and refining our methods. This poses a fundamental challenge to the scalability of this type of work, as the cost is directly proportional to the number of individuals who submitted comments to the RFC. For example, what would we have done if 100,000 people responded to the NTIA’s request? Our final run took approximately ~8 hours to complete and cost around $1000. What particular score on our evaluation would lead us to believe we had exercised the requisite amount of rigor to prove that our system could extrapolate and perform at an acceptable level?
There are certainly other limitations of our methodology, though overall, we feel relatively confident that, at least for the questions we ended up with and the dataset we were working with, we were able to answer questions in a way that seems likely to have been relatively accurate. However, it is critical to remember that this was only possible because of our iteration on those questions — naively asking an LLM random questions about a set of documents does, empirically in the case of this dataset, lead to significantly less accurate results.
Conclusions
In this post, we presented a methodology for using LLMs to answer questions about a large body of text documents, using our analysis of the NTIA RFC as a particular example. We make no claims that this methodology applies beyond the scope of this particular analysis, though we hope that the extra details at least help to inspire confidence in the numbers that we report in our associated blog post, as well as to justify the decisions that we made during the project. We also highlighted some serious limitations, both of the dataset itself (and the strength of conclusions that can be drawn from it) and, to a lesser extent, our analysis choices and the level of confidence that we can have in our results.
In the future, we hope to see improved AI systems which are both more ergonomic to work with, and which can be more easily used to reach accurate conclusions more quickly. Until that point though, we would highly recommend that users of these systems take care and use good judgment in applying them to specific situations, spending time to dig into the data and validate that the results they are getting are in fact reflective of reality, and ideally share that work with downstream consumers of that information to foster trust and reproducible analyses.
Appendix
Appendix A: human study design considerations
We took a number of steps to ensure that our human data was collected in an ethical and appropriate manner:
- We designed our studies so that a participant could complete them in around 20 minutes, and aimed for a payment corresponding to $15/hour.
- If a participant exceeded our time estimate substantially, they were automatically timed out and we manually awarded them a bonus payment for their participation.
- Since some of the submissions contained some mild profanity (such as cursing or discussion about graphic content or AI-generated pornographic imagery), we included a warning and asked participants to opt out of our study if they wished to not be exposed to profanity.
Appendix B: instructions given to human participants
To instruct human participants on the labeling task, we provided these instructions on separate screens:
- This task concerns comments that were submitted to a government agency, the NTIA, about Artificial Intelligence (AI) accountability.
- Your task is to read submissions to the NTIA’s request for comment and answer short questions about them.
- You will have to read 6 submissions and answer 19 questions about each submission.
- To finish the task in the estimated time, you should aim to read each submission in about 1 minute and answer each question in about 5-10 seconds.
- Some submissions may contain mild profanity. If you are uncomfortable reading those, please return the study.
- Before you begin, please answer the following quiz questions to confirm the instructions are clear.
Next, we instructed participants to answer three quiz questions:
- Which government agency solicited the request for comment? Correct answer: NTIA, Alternatives: CIA, IRS, FBI
- What does AI stand for? Correct answer: Artificial Intelligence, Alternatives: Automobile Insurance, Average Income
- How many submissions will you be asked to read? Correct answer: 6, Alternatives: 4, 8, 10
If participants failed any of these simple questions, we instructed them to re-read the instructions and re-do the quiz. We set up our task to automatically exclude any participants who failed the quiz three times, but this never occurred in practice.
Finally, after a participant read a submission, we presented them with a multiple-choice question “which of the following sentences appeared in the submission you just read”, with as choices:
- a random sentence from that submission
- a random sentence from a random different submission.
References
- For our analysis on the organizational submissions, see this post.
- We verified there was never any ties, i.e. the language model never responded with Yes, No and Unsure for a single question.