
Vincent Sitzmann, MIT: On neural scene representations for computer vision and more general AI
RSS · Spotify · Apple Podcasts · Pocket Casts
Vincent Sitzmann (Google Scholar) (Website) is a postdoc at MIT. His work is on neural scene representations in computer vision. Ultimately, he wants to make representations that AI agents can use to solve the same visual tasks humans solve regularly, but that are currently impossible for AI. His most recent paper at NeurIPS presents SIREN, or Sinusoidal Representation Networks, which is an MLP network architecture that uses the periodic sine as its non-linearity. This aims to solve the problem current networks have where they struggle to model signals with fine detail and higher order derivatives.

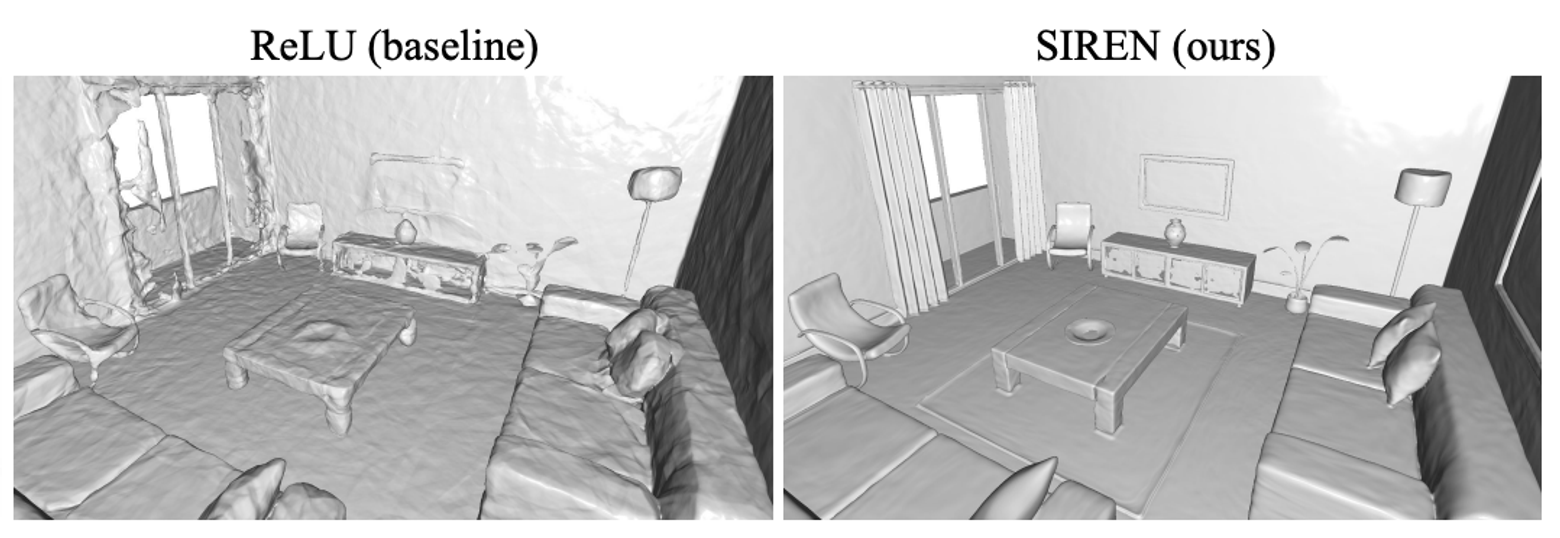
Highlights from our conversation:
👁 “Vision is about the question of building representations”
🧠 “We (humans) likely have a 3D inductive bias”
🤖 “All computer vision should be 3D computer vision. Our world is a 3d world.”
Below are the show notes and full transcript. As always, please feel free to reach out with feedback, ideas, and questions!
Some quotes we loved
[05:52] Vincent’s research:
“Vision is fundamentally about the question of building representations. That’s what my research is about. I think that many tasks that are currently not framed in terms of operating on persistent representations of the world would really profit from being framed in these terms.”
[08:36] Vincent’s opinion on how the brain makes visual representations:
“I think it is likely that we have a 3d inductive bias. It’s likely that we have structure that makes it such that all visual observations that we capture are explained in terms of a 3d representation. I think that is highly likely. It’s not entirely clear on how to think about that representation because clearly it’s not like a computer graphics representation…”
“Our brain, most likely, also doesn’t have only just a single representation of our environment, but there might very well be several representations. Some of them might be tests specific. Some of them might be in a hierarchy of increasing complexity or increasing abstractness.”
[15:32] Why neural implicit representations are so exciting:
“My personal fascination is certainly in this realm of neural implicit representations, it’s a very general representation in many ways. It’s actually very intuitive. And in many ways it’s basically the most general 3d representation you can think of. The basic idea is to say that a 3d scene is basically a continuous function that maps an XYZ coordinate to whatever is at that XYZ coordinate. And so it turns out that any representation from computer science is an instantiation of that basic function.”
[21:17] One big challenge for implicit neural representations, compositionality:
“Right now, that is not something we have addressed in a satisfying manner. If you have a model that is hierarchical, then inferring these hierarchies becomes much harder. How do you do that then? Versus, if you only have a flat hierarchy of objects that you could say, every object is separate, then it’s much easier to infer which object is which, but then you are failing to model this fractal aspect that you talk about.”
[26:08] The binding problem in computer vision:
“Assuming that you have something like a hierarchy of symbols or a hierarchy of concepts given a visual observation, how do you bind that visual observation to one of these concepts? That’s referred to as the binding problem.”
[31:52] What Vincent showed in his semantic segmentation paper:
“We show that you can use these features that are inferred by scene representation networks to render colors, to infer geometry, but we show that you can also use these features for very sparsely supervised semantic segmentation of these objects that you’re inferring representations of.”
[56:13] Gradient descent is an encoder:
“Fundamentally, gradient descent is also an encoder on function spaces. If you think about the input out behavior, if you say that your implicit representation is a neural network, then you give it a set of observations, you run gradient descent to fit these observations and outcomes, your representation of these observations. So gradient descent is also nothing else but an encoder.”
Show Notes
- Vincent biography and how he developed his research interests [01:52]
- Why did Vincent pursue computer vision research, of all things? [03:10]
- The paper that inspired Vincent’s idea that all computer vision should be 3d vision - Noah Snavely’s Unsupervised depth and ego motion [4:47]
- How should we think about scene representation analogs for the brain? [07:19]
- What Vincent thinks are the most exciting areas of 3d representations for vision right now: neural implicit representations [15:32]
- The pros and cons of using implicit neural representations, and comparing them to other methods (voxel grids, meshes, etc.) [15:42]
- How might we build in hierarchical compositionality into implicit neural representations? [20:14]
- Why is solving the problem of vision so important to building general AI? [25:28]
- Vincent’s paper on DeepVoxels . Why might they still use this method? [27:05]
- What areas of his research does Vincent think may have been overlooked? (focusing on computer vision problems rather than the AI problem) [28:51]
- How can we make scene representation networks more general? [30:36]
- Vincent’s paper on Semantic Implicit Neural Scene Representations with Semi-Supervised Training . How can we use inferred features from implicit NNs for sparsely supervised semantic segmentation? Why does it work? [32:19]
- If humans are able to intelligently form visual representations without a great internal lighting model, how might we build better “bad visual models” to better represent intelligence? [35:25]
- How might Vincent make for completely unsupervised semantic segmentation? [41:52]
- How might using 2.5D images be better than using 2D images? [42:31]
- How would we do scene representations for things that are deformable, rather than posed objects? [44:07]
- What unusual or controversial opinions might Vincent have? [47:57]
- Vincent’s advice for research [48:10]
- All computer vision should be 3D vision, not 2D & continuous representations seem to fit better [49:07]
- Why shouldn’t transformers work so well in theory? [51:03]
- Papers that affected Vincent: Noah Snavely and John Flynn on DeepView (novel view synthesis with neural networks), David Lowe on Unsupervised Learning of Depth and Ego-Motion from Video , Ali Eslamai on Neural scene representation and rendering ( steering the conversation towards unsupervised neural scene representation via neural rendering [53:18]
- Vincent’s Meta-SDF paper and his opinion on gradient descent as an encoder [53:35]
- What does Vincent think are the most important open questions in the field? [1:01:22]
- What are the practical applications of SIREN? (sinusoidal representation networks / periodic activation functions for implicit neural representations) [1:02:59]
- Vincent’s thoughts on what makes for a good research environment and good researchers [1:04:54]
Thanks to Luke Cheng for writing drafts of this post and Tessa Hall for editing the podcast.