
General purpose AI agents need “reasoning” capabilities to process and interpret information. Large language models (LLMs) have the potential to play that role because of their remarkable power.
Given this possibility, we recently investigated the reasoning potential of LLMs – particularly, how they perform on ethical topics. We presented our findings at the ML Safety Workshop at NeurIPS in December.
Our core claim is that current LLMs do not reason in the same way as humans; we show numerous examples of how GPT-3 can easily be made to fail systematically using simple rewordings of ethical scenarios. We also looked at how humans failed on the same scenarios and found that the error rate was higher, but for different reasons (e.g., clicking on the wrong answer).
As a team, we do a substantial amount of work with LLMs, and one of our key research priorities is studying how they work, and the ways they fail, so that we can use them safely. This paper is an example of those efforts and shows that LLM ethical reasoning is a distinct process from human reasoning.
LLMs are complex statistical models of language
Since LLMs are probabilistic estimators of the likelihood of the next token in a sequence, there is no a priori reason why we should expect them to reason like humans, and our findings confirm this.
Prompting superhuman performance, and breaking it with simple rewordings
To better understand how LLMs might function as ethical reasoners, we used GPT-3 completions to classify examples from the common sense portion of the ETHICS dataset.
By using a technique we call SimPrompting, we were able to exceed the average performance of even human labelers (mTurk masters).
However, when we took a more adversarial approach, we found that we could easily construct minor rewordings of existing scenarios that would mislead the LLM – without really changing the meaning of the scenario. This table shows examples of scenarios that GPT-3 labeled incorrectly after we reworded them:

Naive scaling can make things worse
Our discovery that it was so easy to trick these systems led to a natural question: would this phenomenon disappear with much larger models?
The answer to this question appeared to be no, as we found that in many cases LLM performance and scale were actually anti-correlated, with the model adopting greater certainty in the wrong answer as scale increased up to the level of GPT-3.
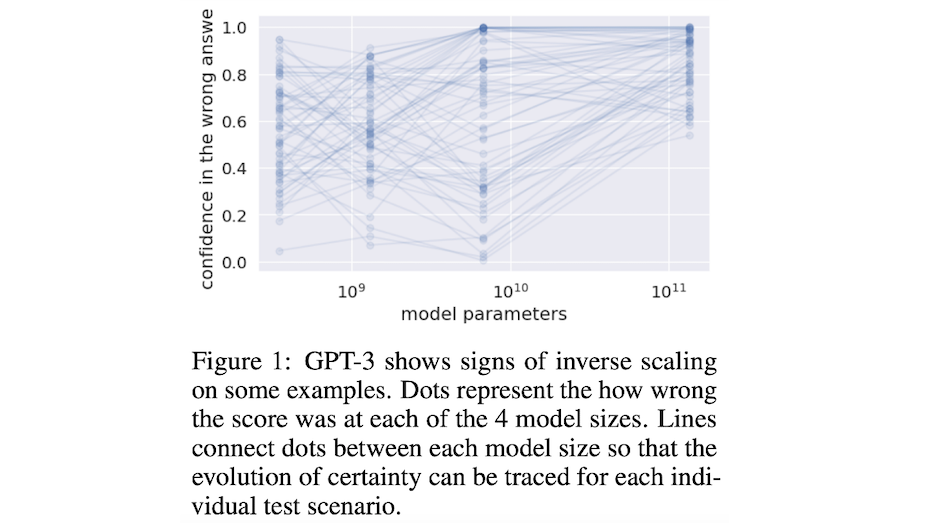
Analyzing human and machine errors
The paper also contains a detailed breakdown of the errors made by both GPT-3 and by human raters. From analyzing the errors, it becomes very clear that LLM-based systems are not reasoning about these scenarios in the same way as people. However, on average, their performance is higher because people make other types of mistakes (e.g., clicking on the wrong button, misreading the scenario).
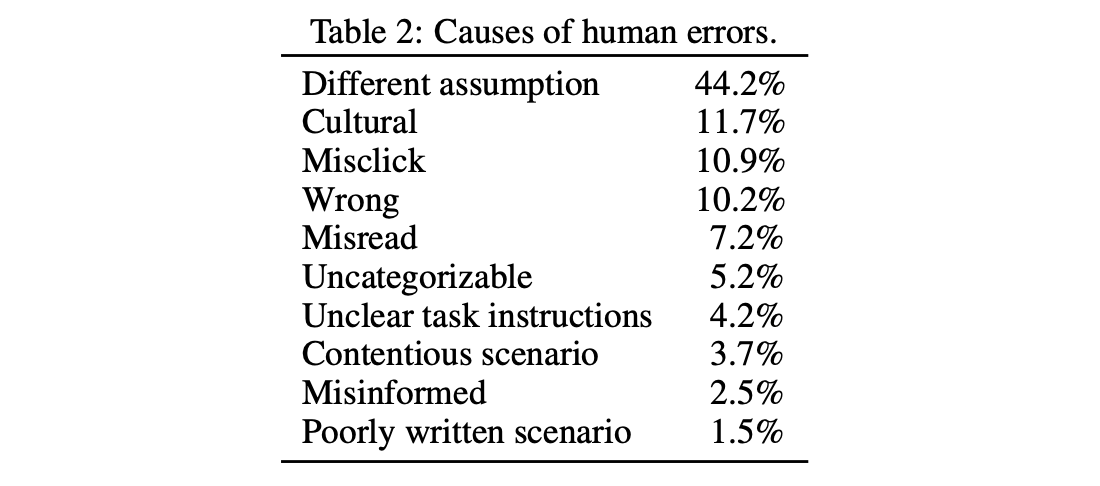
One of the more interesting takeaways for us was how often people made various types of mistakes, including justifying the wrong answer in an obviously incorrect way. People are not perfect ethical reasoners, but their errors are different in kind from LLMs.
The path forward
We are extremely excited about what can be built on top of LLMs, but today they’re not suitable for cases where they must reason about moral situations. Significant work remains to be done to improve their robustness and our understanding of how they work (and where they fail). It will also be important to have a better theoretical understanding of the correspondence between human reasoning processes and the operations happening in LLMs.
If you’re excited to help develop a deeper understanding of reasoning, LLMs, and how they can be safely and robustly deployed in the real world, we’re hiring!
Learn more
Check out the paper for more detail as well as a comprehensive discussion of related work.
To cite, use the following:
@ARTICLE{Albrecht++22,title={Despite "super-human" performance, current LLMs are unsuited for decisions about ethics and safety},author={Albrecht, Joshua and Kitanidis, Ellie and Fetterman, Abraham J},journal={arXiv preprint arXiv:2212.06295},year={2022}}