
- Key learnings
- How code review broke a correct bug fix
- Zooming out: what happens across all tasks?
- The invisible value: code quality improvements
- Actual lifts: review helps fix more
- Regressions: rare but real
- Practical guidance
- Appendix
- Benchmark and task selection
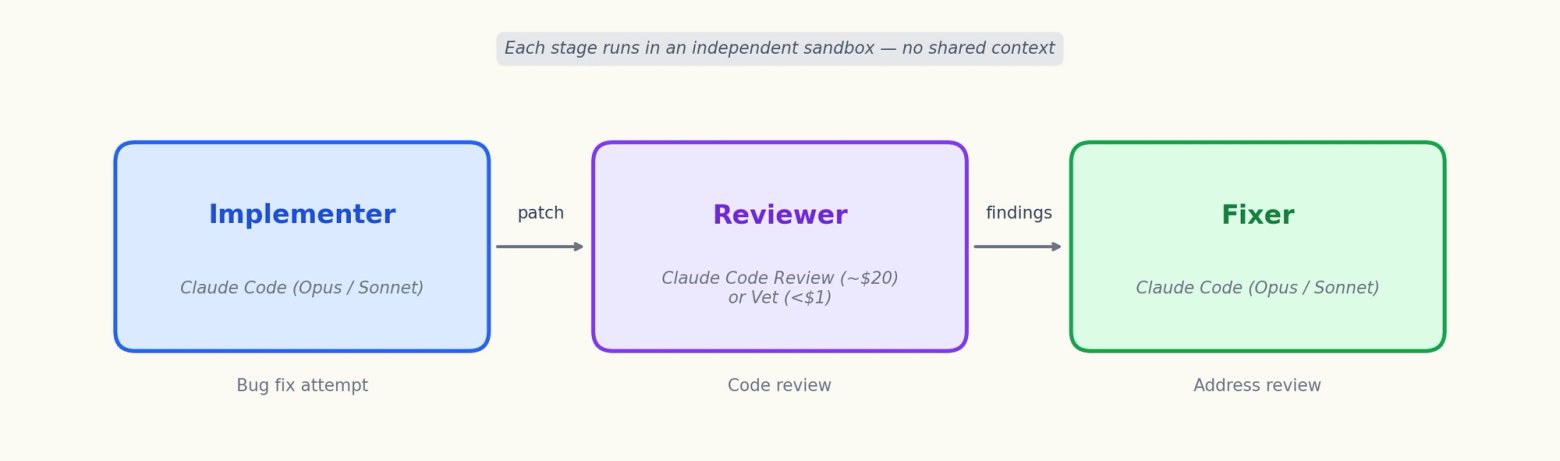
- Pipeline
- Eval protocol
- Fixer prompt templates
- References
Code review has been essential in software development, at least while humans drove the changes. But what happens when you replace both the PR author and the reviewer with AI agents? We built such an agent pipeline and tested it on SWE-bench Pro Python tasks. An implementer wrote code, a reviewer generated PR comments, and a fixer addressed the comments.
The mean score did not move statistically significantly, but we learned something interesting to share.
Key learnings
AI reviewers flag legitimate issues. But when a weaker fixer agent addresses them, it sometimes makes changes beyond the scope of the review. We call this overreach, and it’s how automated code review can make correct code worse. We found that softening the instructions to the fixer reduces regressions.
Read on for the experimental setup, what we mean by “softening instructions”, and how code review delivers improvements beyond what benchmarks can measure.
How code review broke a correct bug fix
A strong agent (Claude Opus) fixes a qutebrowser color parsing bug (HSV hue percentages were scaled wrong), passing all tests.

A code reviewer Vet1 examines the patch:
“No regression tests added. Add tests covering percentages and boundary values.”
A weaker agent (Claude Sonnet) addresses the review. It adds the requested tests. But while it’s there, it tries to “improve” the math by rewriting the rounding logic. It then runs pytest. One test fails. The agent logs:
“There’s one failing test (rgba(255, 255, 255, 1.0)) that’s unrelated to our changes”It ships the code.
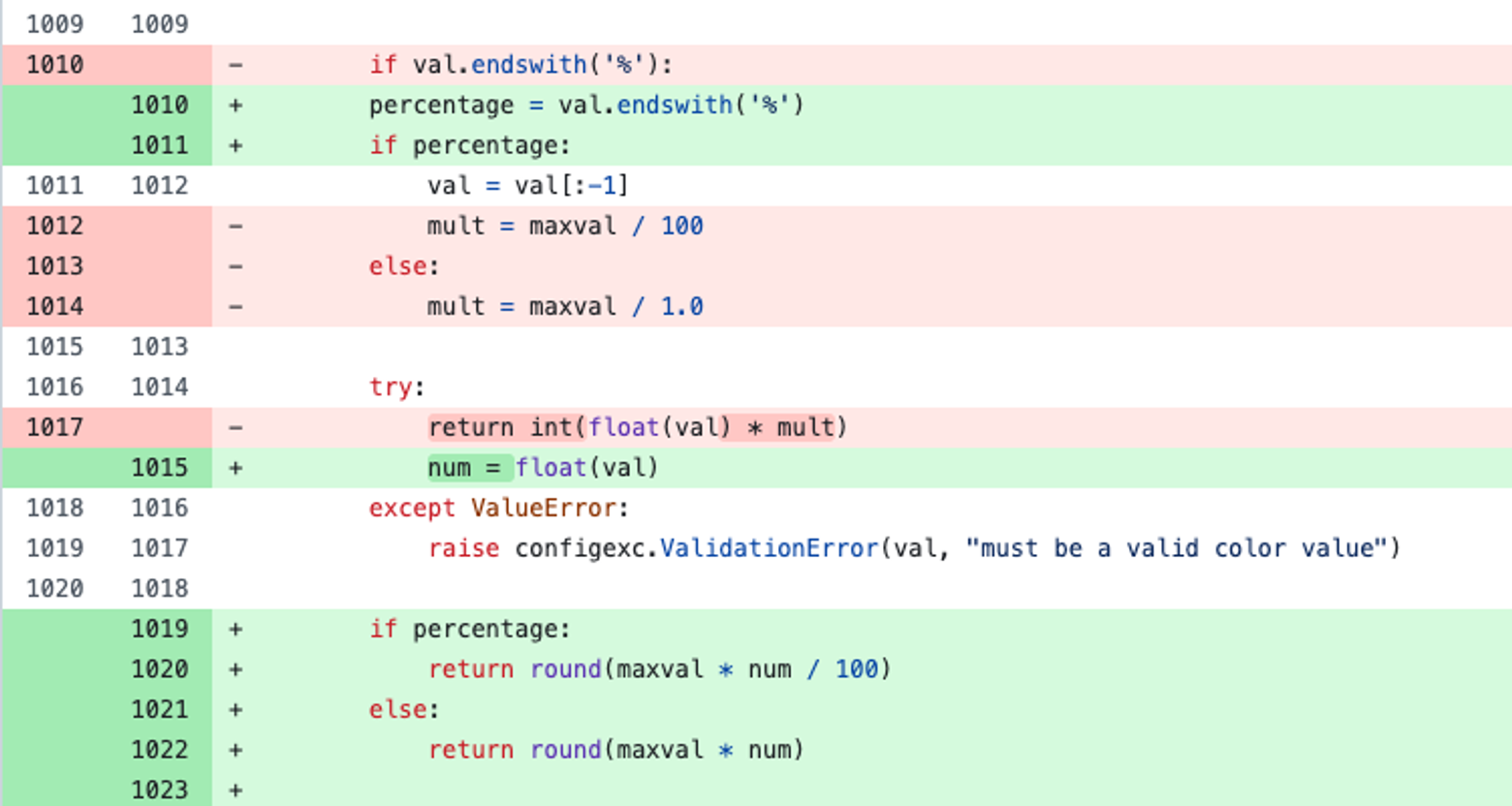
However, the failing test is caused by the change. The fixer agent just couldn’t connect its own math change to the broken test.
Zooming out: what happens across all tasks?
We ran this pipeline, implementer → reviewer → fixer, on SWE-bench Pro tasks across ansible and qutebrowser. (See Pipeline below for the full setup.)
The invisible value: code quality improvements
In more than 70% of trials, the score doesn’t change. But that doesn’t mean the reviewer and fixer did nothing. The reviewer flagged genuine issues, and the fixer made real changes, sometimes substantial ones. They just didn’t affect the specific tests the benchmark evaluates against.
- qb-01d1d149: Vet flagged that
_initializedis never set toTrueafter_initialize_info()runs. Every call toget_version()redundantly re-initializes. The fixer addedself._initialized = True. (diff)
These kinds of changes don’t move benchmarks, but the quality improvement will compound in real codebases.
Actual lifts: review helps fix more
On some tasks, the reviewer discovers real issues the implementer introduced, and the fixer resolves them. This results in a lift in f2p gains (fail-to-pass: tests that verify the bug is fixed).
- an-be59caa5: The implementer added ipset match support to Ansible’s iptables module, scoring 22/23 and failing the hidden test. Claude Code Review (CCR) identified two issues. All four fixer configurations, regardless of model or review format, addressed the review issue correctly and scored 23/23. Consistent lift. (diff)
Regressions: rare but real
Like the rgba regression in our opening story, regressions do happen. To understand them better, we designed a controlled experiment: we took 15 tasks where the implementer already passed all tests (fully resolved), ran code review (Vet) on them, and had fixers address the findings.
What did the reviewer flag on correct code?
Of 15 resolved tasks, the reviewer found issues in 8. The breakdown:
| Issue type | Count | Description |
|---|---|---|
| `test_coverage` | 6 | “Add tests for this new functionality” |
| `logic_error` or `runtime_error_risk` | 2 | Real issues or potential edge cases |
What happened after the fixer addressed them?
Most tasks stayed the same. The fixer added tests or made minor fixes without breaking anything.
But one task regressed. The fixer made changes beyond the immediate scope of the review finding, and that led to a regression. This is a common pattern among the regressions we observed. We call it overreach.
To understand more about this overreach behavior, we ran an experiment varying the review detail level.
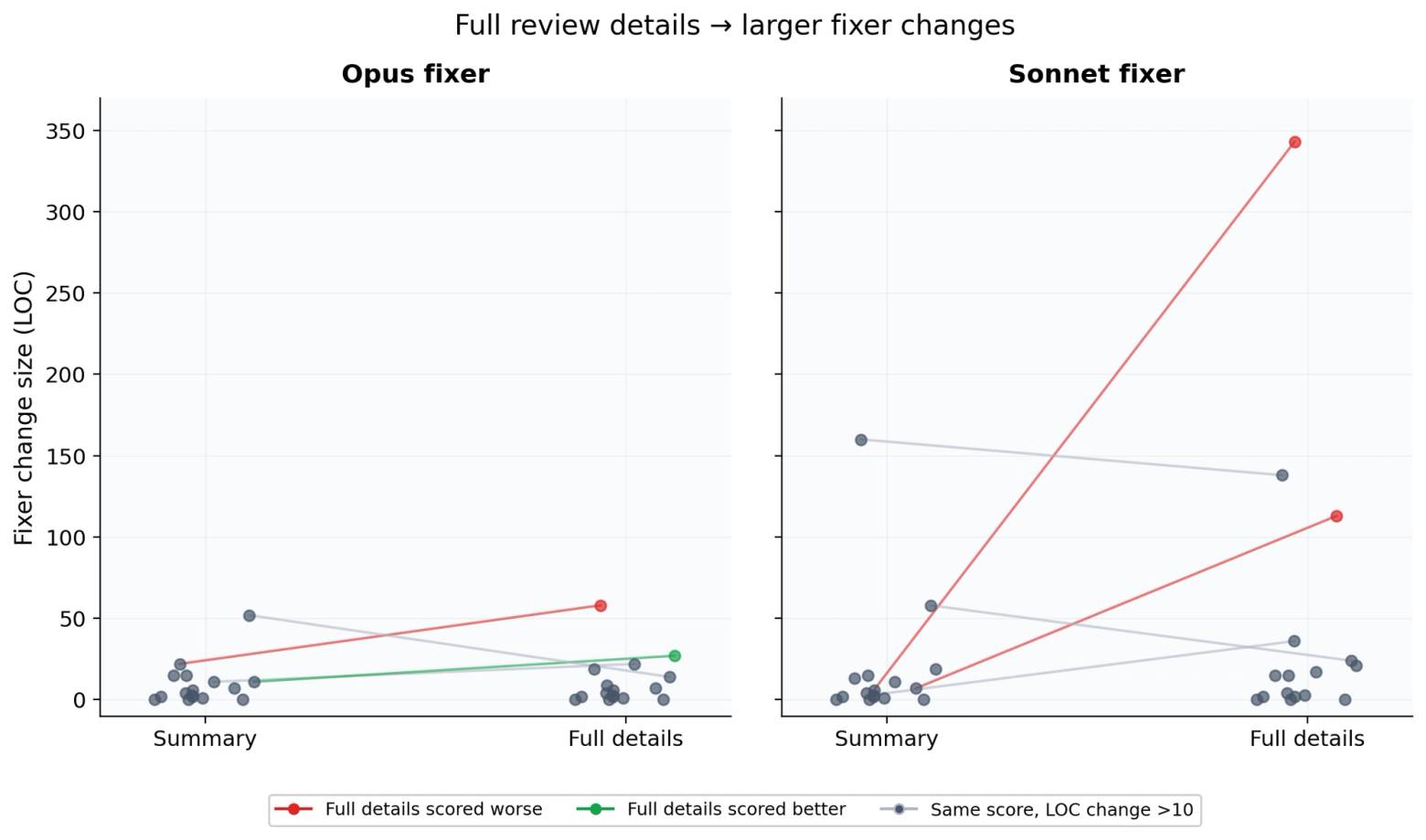
More detail enables overreach
We tested full Claude Code Review (CCR) comments (with <details> reasoning, over 6k chars) versus summary-only comments (stripped to under 1k chars).
an-4c5ce5a1: The implementer (Opus) refactored Ansible’s selinux integration, wrapping the native C library in a compatibility layer used across 10 files (impl patch). It scored 16/17. CCR then flagged three quality issues: a memory leak in selinux ctypes (hard), a double-period typo (easy), and dead code (easy). We then fed these to a Sonnet fixer with various detail levels. The reviewer’s <details> sections are well-written, but the extended bug analysis gives Sonnet enough context to invent its own approach and get it wrong.
- Summary only: Addressed all quality issues. Added
freecon()for the memory leak, corrected the typo, removed dead code. 4 lines of source changes. Score unchanged at 16/17 (p2p: 7/8, f2p: 9/9). (diff) - Full details: Restructured the selinux integration across 8 files with 113 lines, resulting in a score of 8/17; all 9 f2p tests now fail. Δ=-8. (diff)
Measuring overreach: detail leads to more changes
We measured how many lines of code each fixer changed relative to the impl across 64 trials across 16 tasks.
| Fixer / Format | Avg LOC | Max LOC |
|---|---|---|
| opus / full | 11 | 58 |
| opus / summary | 9 | 52 |
| sonnet / full | 46 | 343 |
| sonnet / summary | 19 | 160 |
Full details cause Sonnet to make significantly larger changes.
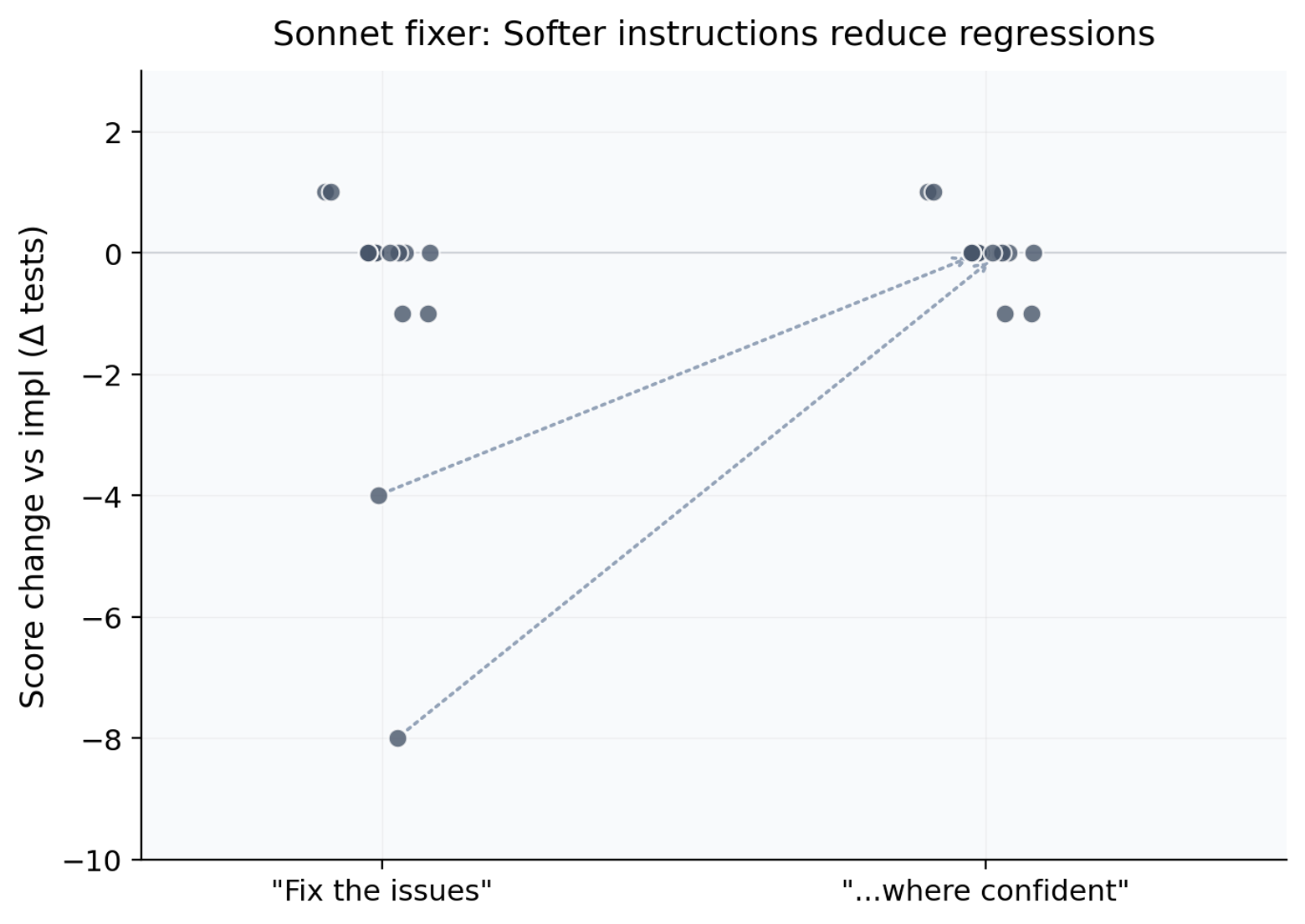
The one-sentence fix
The original fixer prompt says: “Fix the issues identified.” We introduced softer instruction variants for the fixer, such as “Address the issue when confident.” The specific wording didn’t tend to matter. Any permission to skip hard issues was sufficient. All softer variants reduced Sonnet’s overreach and eliminated catastrophic regressions, while Opus was largely unaffected.
Practical guidance
- Invest in the fixer. Its quality matters. If you’re auto-fixing review issues with agents, use softer instructions to let the fixer skip hard issues. Let humans focus on what it skips.
- Review in the loop, not just at the PR stage. Review at the PR stage is useful, but it’s even better to add a review step inside the agentic loop, catching issues on small changes before they compound. Stay tuned for a future post on agentic review setup best practices.
Appendix
Benchmark and task selection
We selected 175 Python tasks from SWE-bench Pro.
We ran all tasks to establish implementer baselines, then selected subsets for different experiments. Partial-score tasks (some tests passing) give room for both lifts and regressions. Fully-resolved impl patches (all tests passing) make it easier to isolate review-plus-fix damage on working code.
Pipeline
Each task goes through 3 independent stages, each in its own sandbox with no shared Claude session or conversation context:
- Implementer: Claude Code CLI agent (
max_turns=200, 1h timeout) attempts the bug fix in a per-task Docker image from SWE-bench Pro. - Reviewer: Claude Code Review (GitHub-managed, inline PR comments with
<details>reasoning) or Vet CLI (structured JSON output). - Fixer: Claude Code CLI agent addresses review findings in a fresh sandbox with the impl patch pre-committed. Tests are hidden from the agent.
Eval protocol
Each patch (impl and fixer separately) is evaluated in a fresh Docker container with a pristine repo and pre-baked tests.
- Eval runs per patch: 4 runs; we use the minimum score. (A flaky impl is considered failing the test.)
- Metrics:
passed / total, decomposed intof2p(fail-to-pass: hidden tests verifying the task) andp2p(pass-to-pass: pre-existing tests that should still pass). - Delta: fixer score minus impl score. Positive = lift, negative = regression.
- Statistical test: Wilcoxon signed-rank.
Fixer prompt templates
markdownInstruction variants
- Baseline:
Fix the issues identified in the review comments. - A softer variant:
Address the issues identified in the review comments when you are confident the fix is correct. - A softer variant:
Review the issues. For each, decide whether you can fix it safely without breaking existing behavior. Skip any issue where you are not confident.