
Key take-aways
- Our code evolution method improves the reasoning capabilities of cheap models by 2x-3x.
- We set a new record of 34% for ARC-AGI-2 performance using open-weight models. Our method also achieves 95% when using Gemini 3.1 Pro, comparably to current SOTA for closed-weight models.
- Our method can be applied across a wide range of reasoning and optimization tasks.
Our results
The ARC-AGI (Abstraction and Reasoning Corpus) benchmark was proposed by François Chollet in his 2019 paper ”On the Measure of Intelligence” as a way to measure what he calls general fluid intelligence - the ability of a system to efficiently learn solutions to novel problems.
Today, we share our work on using code evolution to solve ARC-AGI tasks. Our evolution method uses a combination of fitness-based sampling and code mutation to iteratively improve upon an initial solution. The mutation step is driven by an underlying base LLM, but is agnostic to the specific model chosen.
Our approach achieves a 2.8x improvement over the base performance of Kimi K2.5, a 1.8x improvement for Gemini 3 Flash, and achieves a 95% score when using Gemini 3.1 Pro:
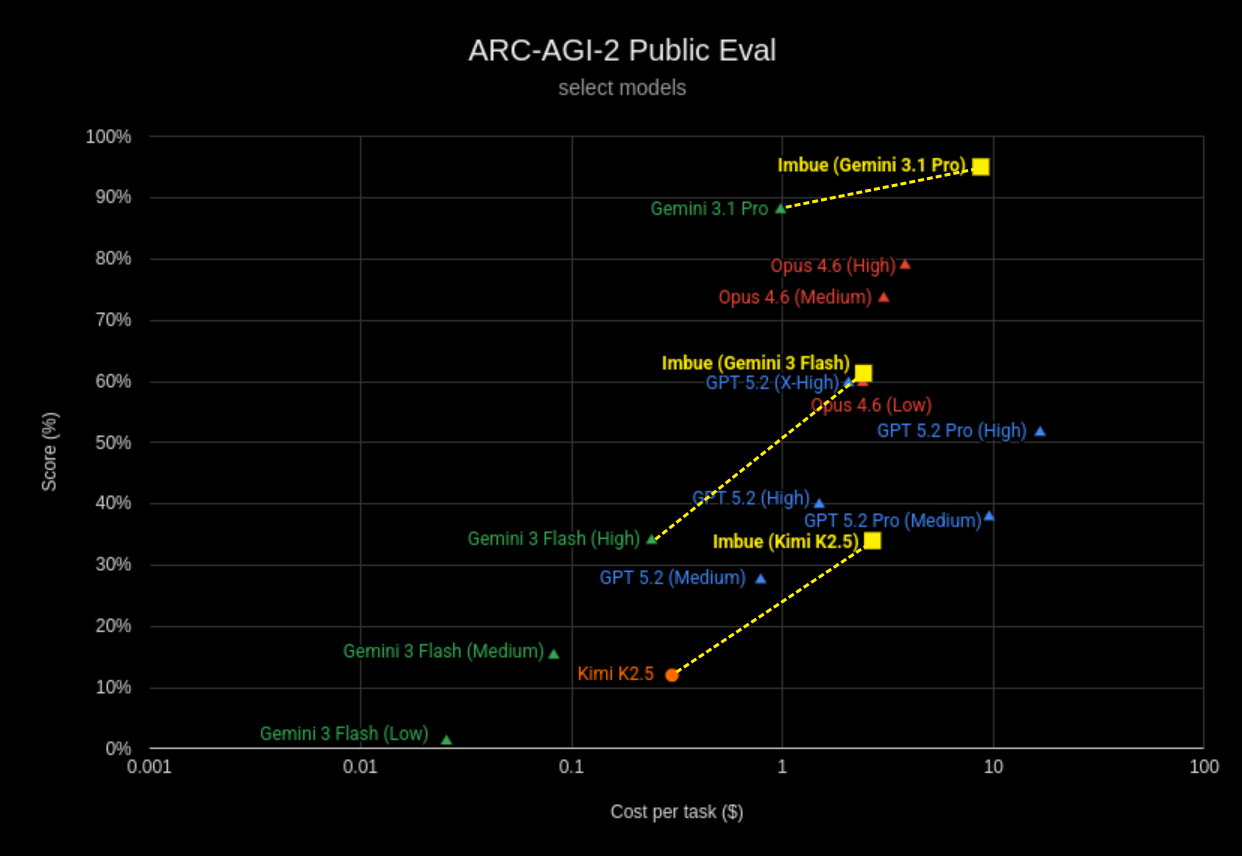
All numbers shown are on the ARC-AGI-2 public evaluation set (source). We also submitted our solution for evaluation on the semi-private data set, but have been informed that the evaluation of new community submissions is currently on hold.
Since not all models and refinements have published results on the public evaluation set, we also show our results super-imposed over the official ARC-AGI-2 leaderboard below. This graph is meant for contextualization only, as scores are not 100% comparable between the semi-private data set used for the leaderboard and the public eval set used for determining our scores.
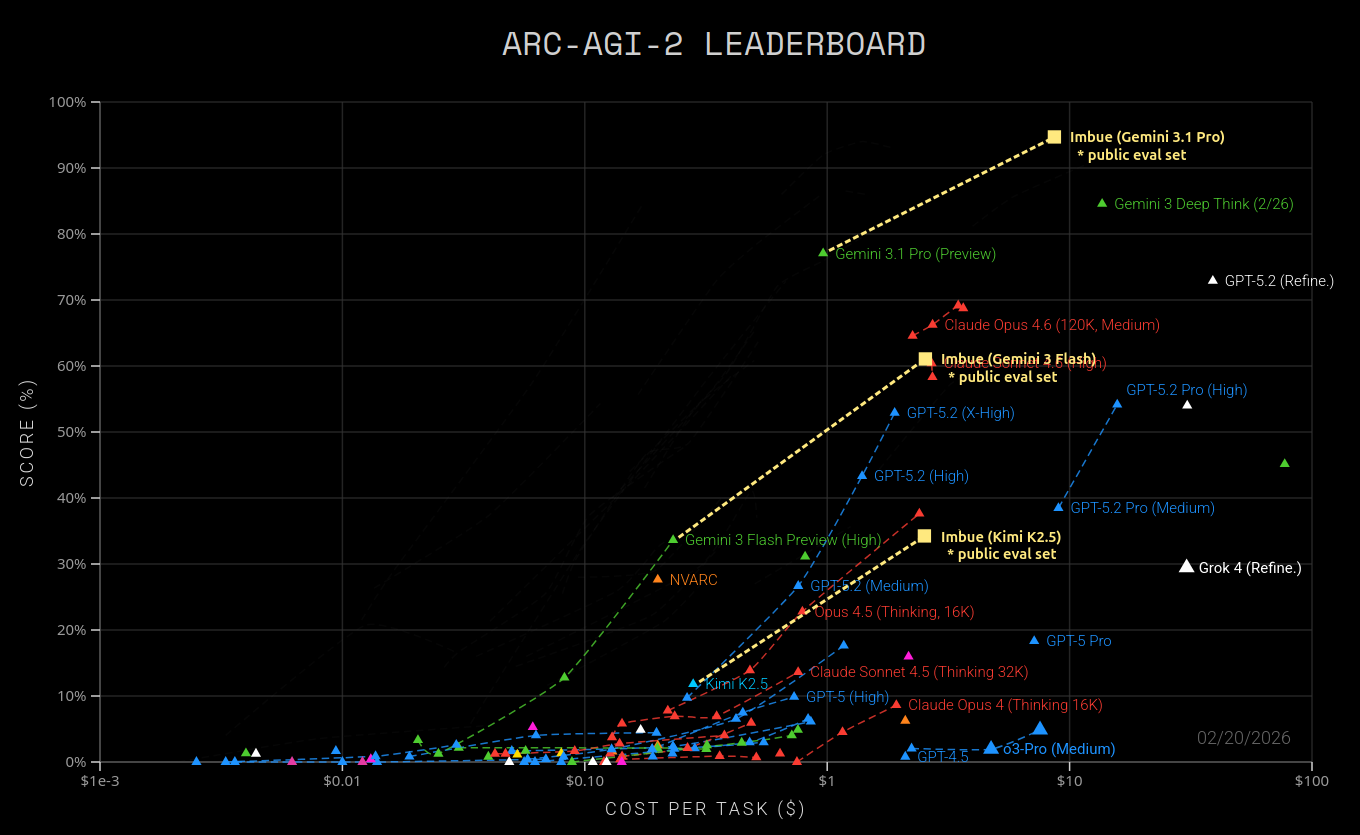
We ran on Kimi K2.5 and on two different models from Google’s Gemini family to illustrate relative performance gains using both weaker and very strong base models. All runs used the exact same evolution framework and prompts.
Kimi K2.5: 2.8x performance gain at $2.67 / task
Using Kimi K2.5, an open-weights model, we obtain a near 3x performance increase, from 12.1% → 34.0% (+21.9%), at $2.67 per task.
To our knowledge, this is the highest performing open-source / open-weights solution for ARC-AGI-2 available today. Our evolution allows an open-weights model to achieve reasoning performance exceeding that of GPT 5.2 on Medium reasoning effort, and approaching that of GPT 5.2 on High effort.
Gemini 3 Flash: 1.8x performance gain at $2.42 / task
Our method boosts the performance of Gemini 3 Flash from 34.0% → 61.4% (+27%), at $2.42 per task. That is 1.8x the performance of the base model, and comparable both in performance and cost to much stronger and newer models such as Opus 4.6 (Low) or GPT 5.2 (X-High).
Gemini 3.1 Pro: 95% accuracy at $8.71 / task
As of February 2026, Gemini 3.1 Pro is the strongest model on the ARC-AGI-2 leaderboard with a publicly available API.
Our evolution-based approach is able to push its performance even further, from 88.1% to 95.1% (+7%). We achieve this at an average cost of $8.71 per task. While our relative performance gain here is less than on Gemini 3 Flash, this is to be expected, as a saturation effect is likely to kick in once we reach into the ~90% performance range. Our cost is still significantly less than the cost of Gemini 3 Deep Think ($13.62 per task on the semi-private set), and that of other recent leaderboard entries in the “refinement” category (>$30 per task).
Our result is competitive with the current state of the art on the ARC-AGI-2 public evaluation set, which was set just this week by Confluence Lab at a reported sore of 97.9% for $11.77 / task.
The ARC-AGI problem
The ARC-AGI benchmark’s data set is made up of several independent tasks. Each task is composed of a small number (typically 2-5) of input/output examples, and of test or “challenge” inputs for which the corresponding outputs are not known. Each input and output consists of a rectangular grid, with a color value in each cell.
Your task is to inspect the example input/output pairs, understand the transformation rule that explains how to obtain the outputs from the inputs, and then apply the transformation rule to predict the outputs for the challenge inputs. The transformation rule is different for each task, and oftentimes requires an understanding of visual patterns, geometric manipulation, and/or rigid mechanics.
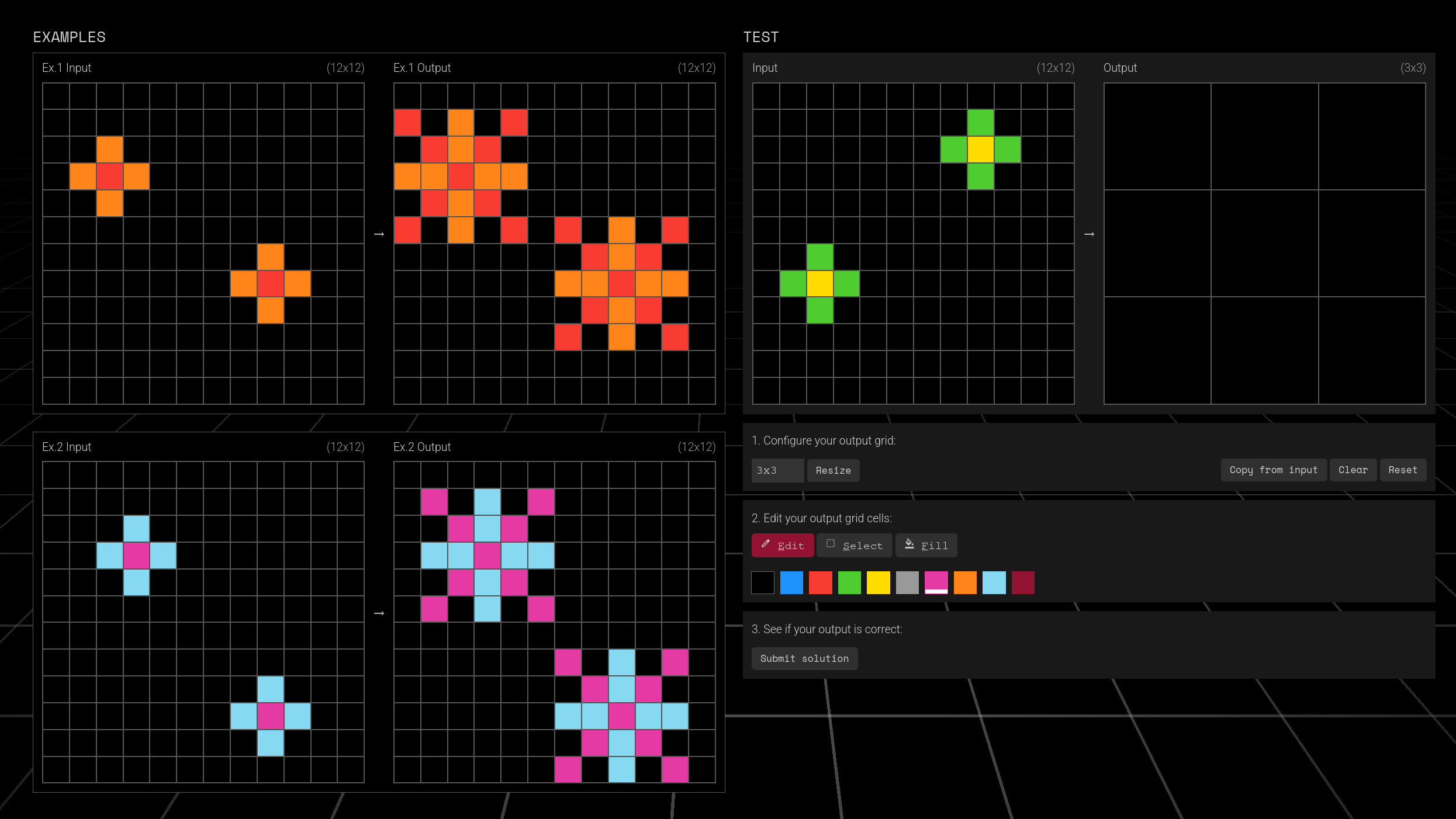
If you’re not familiar with ARC-AGI tasks, we recommend you try solving a few yourself - they’re quite fun!
Solving ARC-AGI tasks has historically been challenging for AI. It took several years for AI methods to reach double-digit success rates in the first iteration of the benchmark, now known as ARC-AGI-1. Early LLMs frequently couldn’t solve a single task. However, reasoning LLMs have improved rapidly on ARC-AGI over the last year. A second (more difficult) iteration of the benchmark, ARC-AGI-2, was released in 2025. At the beginning of 2026, the highest-scoring model was GPT 5.2 Pro with a success rate of 54.2%. At the time of writing, merely two and a half months later, the best-performing model is Gemini 3 Deep Think (2/26), with a success rate of 84.6%.
In the following, we will show how we used code evolution to solve ARC-AGI tasks.
Solving ARC tasks with code evolution
The high-level approach of our solution is as follows: For each given ARC-AGI task, we maintain a population of “organisms”. Each organism represents an attempt at solving the task through a piece of Python code. Starting with an initial organism, we repeatedly sample a parent organism, weighted by its fitness score. We then apply mutations to the sampled parent to generate children. These children get scored and are added back to the population to be sampled in future iterations.
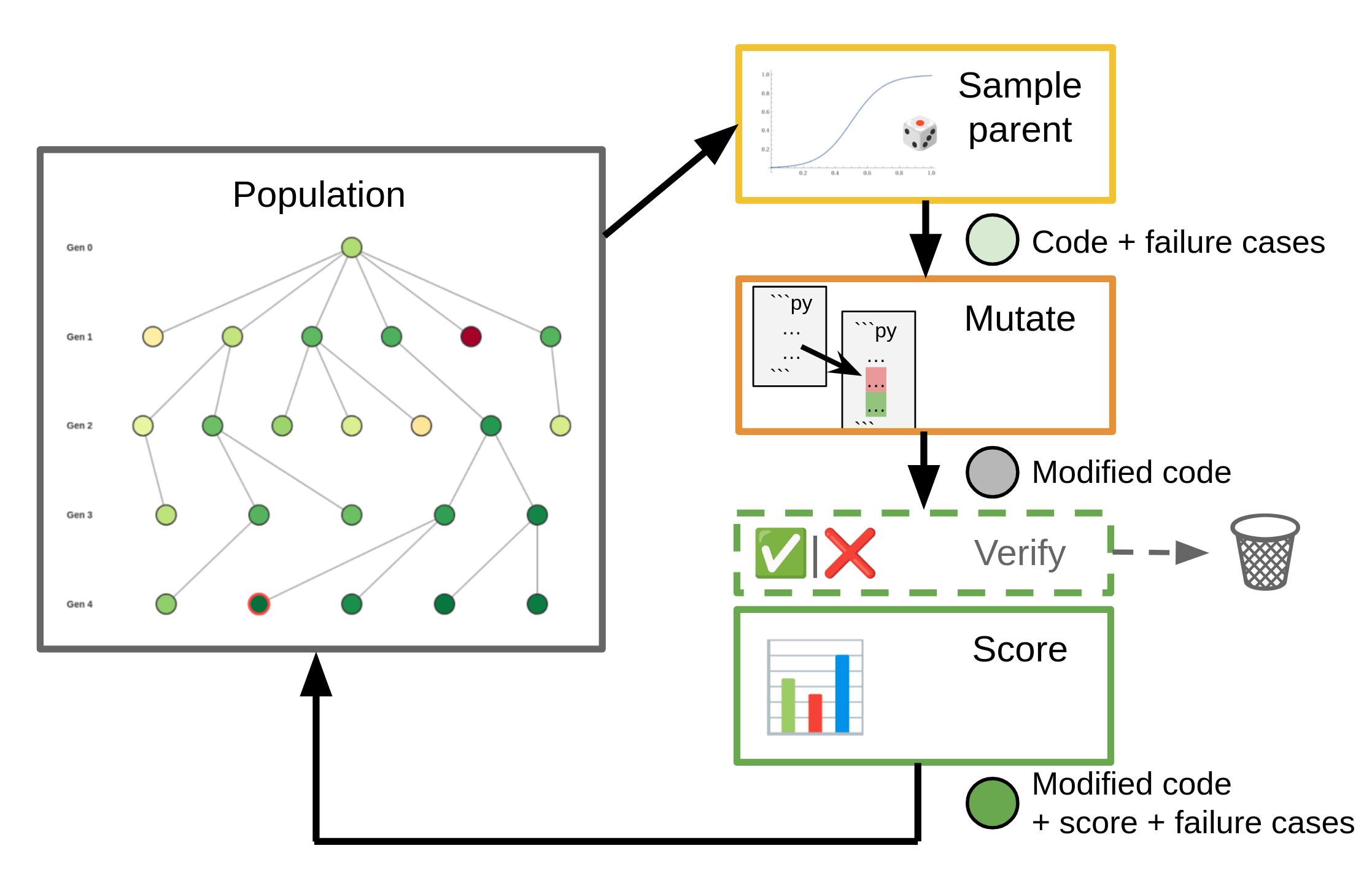
You can read more about our code evolution framework in our separate post.
ARC-AGI transformations as code
We use code to express the transformation rule for a given ARC-AGI task. First, we represent each color as a numeric value (0 - 9) in a 2D input and output grid. Then, we can state the goal of solving an ARC-AGI task as finding a Python function:
def transform(input_grid: np.ndarray) -> np.ndarray:# ...transform input_grid into output_gridreturn output_grid
such that it maps each of the task’s input grids to the corresponding output grids.
To solve a given ARC-AGI task, we always start with the same trivial root organism which simply returns the input grid unchanged:
def transform(grid: np.ndarray) -> np.ndarray:# This is a placeholder --- put your solution here.return grid
We then run the evolution process to derive a better solution. We perform a variable number of iterations, up to some maximum (16 for the results shown below). Once we find two solutions that cross a target score threshold, we stop. This allows us to spend only the amount of compute needed to solve a given task, with most tasks stopping well before reaching the iteration maximum.
ARC-AGI permits us to submit two solution attempts for each task. As long as either one is correct, the point is granted. Therefore, we select the two best-scoring distinct outputs for each given challenge input to form our final solution.
Mutating ARC-AGI solutions
We use a reasoning LLM to generate mutations of a given transform implementation. The LLM is given each example input/output pair and the challenge inputs from the current ARC-AGI task. Additionally, the LLM is given the parent’s existing solution, and receives feedback about the performance of that solution. More specifically, we provide an overall accuracy score for each example output, and a rendering of the output grid in which incorrectly predicted cells are highlighted.
Our solution makes use of the following additional prompting techniques to improve mutator efficiency:
- Natural language explanation first: Before producing Python code, we ask the LLM to output a natural language description of the transformation rule. We hypothesize that asking the LLM to reason in natural language rather than code helps align its priors better with human visual language. We also experimented with using natural-language only as the representation on which mutation acts. However, we did not observe a significant performance gain from doing so, and to the contrary observed a large increase in LLM inference cost when using natural language transformation rules exclusively.
- Differential example formatting: When the dimension of the output grid equals that of the input grid, we provide an additional version of the example output where only changed cells are highlighted. This appears to help the LLM focus on the parts of the grid that are actually being affected by the transformation.
- Randomized mutation strength: We randomly prompt the LLM with different guidance regarding the desired magnitude of the mutation. We either ask it to make small incremental changes to the parent, or to think “outside the box” and consider a major reinterpretation of the data. This technique increases the chance of escaping local maxima in the population without sacrificing gradual improvements.
After generation, the mutated code is executed on the example and challenge inputs. A mutation is only accepted into the population if it predicts a different result on at least one of the inputs. This post-mutation verification step prevents trivial code modifications from over-powering more meaningful changes in the population.
We also use crossover mutations to combine new discoveries from across the population. The crossover mutator runs 25% of the time and samples three parents from the population instead of just one. Its prompt asks the LLM to inspect each parent’s performance and combine their transformation rules into a single child solution.
Scoring ARC-AGI solutions
In the evolution paradigm, it is critical to assign meaningful fitness scores to each organism.
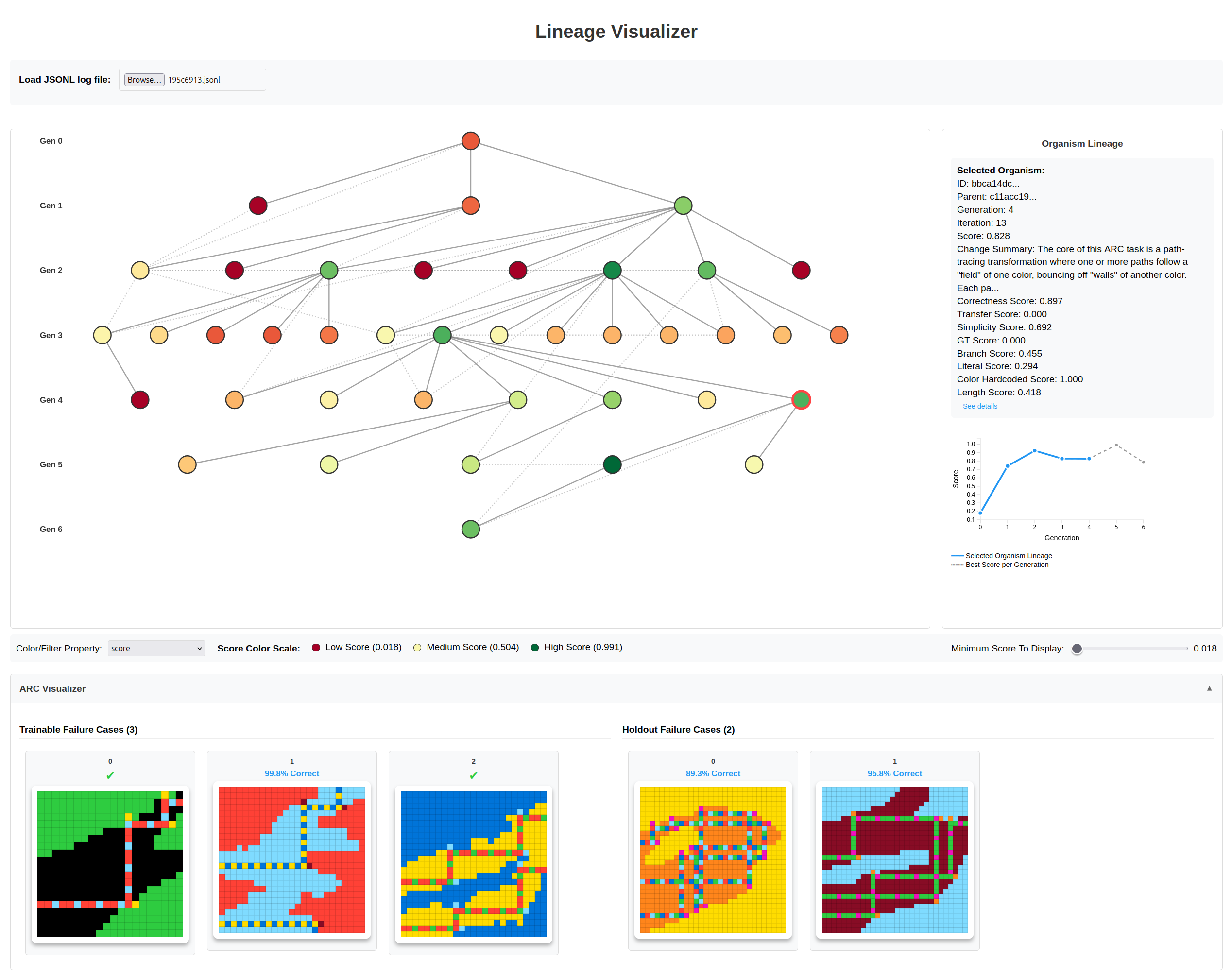
The obvious way to score a code-based ARC-AGI solution is to run the code on each example input of the given task, and calculate how closely the resulting outputs match the provided ground-truth outputs. The screenshot above shows a visualization of the evolution tree for ARC task 195c6913. The selected organism got the first and third examples right (”Trainable Failure Cases”), but still had a some mistakes in its output for the second example.
Unfortunately, ARC-AGI tasks are heavily under-constrained. There is an infinite number of different code solutions that correctly map the example inputs to the correct outputs, while each predicting different results for the challenge inputs. Case in point: While the organism shown above gets two out of three examples right, it fails on both challenge inputs (”Holdout Failure Cases”).
As a guideline, the most “intuitive” solution for us humans is often the right one. However, “most intuitive” does not always mean the exact same thing for an LLM that is trying to write a piece of Python code.
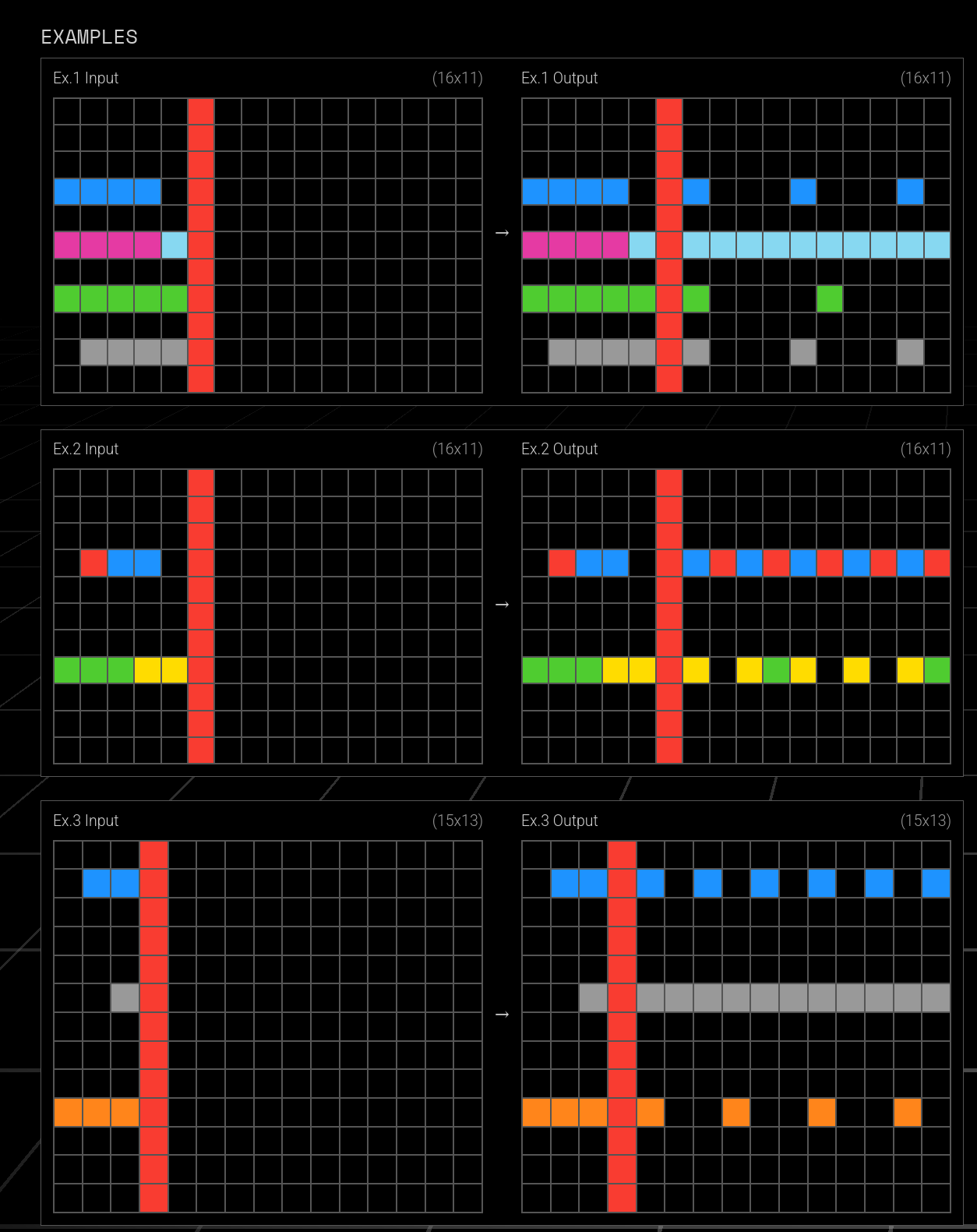
Furthermore, challenge inputs in ARC-AGI-2 oftentimes require additional adaptations or generalizations that did not get illustrated in any of the examples. Task 1ae2feb7 is a good example of this. All three example inputs of this task use a red-colored dividing line, with a seed pattern to its left:
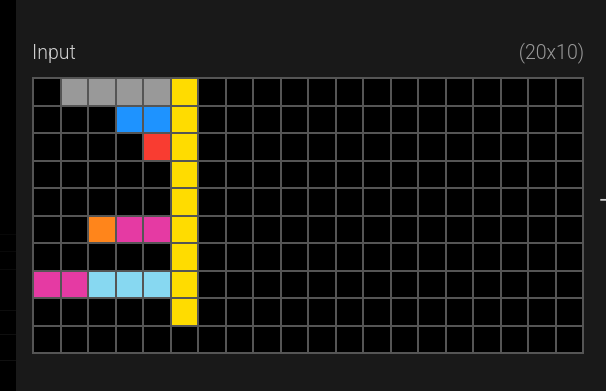
However, the challenge inputs do not follow this rule. One of the challenge inputs uses a yellow dividing line that doesn’t even fill the entire vertical space:
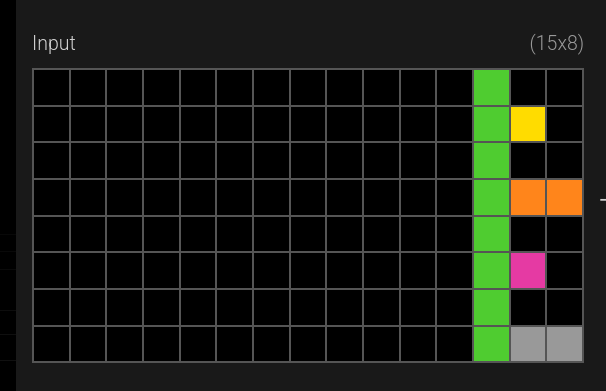
Another one has a green line, with the seed pattern on its right:
When we as humans encounter these challenges, we quickly realize that the “red dividing line pattern” can be generalized to apply to the new variations. In the evolution framework however, we need to explicitly make sure that a better generalizing solution does in fact receive a higher fitness score than one that merely works correctly on the example inputs.
We solve this challenge by introducing two auxiliary scores: The “transfer score”, and a code simplicity score. A solution’s overall fitness score is the weighted average of these three components:
- Correctness on the example input/output pairs (90%): We run the organism’s Python code on each of the task’s example inputs, and compare the results to the known outputs. Partial points are granted for each grid cell that the organism gets correct. The resulting correctness fraction is scaled such that the trivial solution of simply copying the input grid to the output grid is assigned a value of 0.2, and the a fully correct output a value of 0.9. Values below 0.0 are clamped. An additional bonus of 0.1 is granted for a fully correct output to bump the correctness score up to its maximum of 1.0.
- Transfer score (7%): We use a reasoning model to assess how well the proposed solution applies to the challenge inputs. This score can catch a wide range of gaps in a solution’s ability to generalize from the examples to the challenge inputs, such as unnecessarily hard-coded colors or directions, to subtle implementation issues that only surface when running the code on the challenge inputs. (prompt)
- Simplicity score (3%): An LLM or code parser analyses the organism’s Python code to assess its simplicity and generality. Our simplicity score is a combination of multiple different code heuristics: the number of hard-coded constants in the code, the number of hard-coded color values in particular, and the overall length of the code. For each, a lower number corresponds to a higher simplicity score. We’ve found that among solutions that solve the example inputs correctly, those that are simpler along these dimensions have a slightly better chance of providing correct predictions for the challenge inputs as well.
Prior art
The idea of expressing ARC-AGI solutions as code is almost as old as the ARC-AGI challenge itself. Many early approaches used domain-specific languages and code search to derive ARC-AGI solutions. Recently, several prompt refinement approaches over LLM base models have used code to obtain verifiable and evolvable solutions (e.g. Jeremy Berman’s ARC-AGI-1 submission, or Poetiq’s recent solution to ARC-AGI-2).
In the development of our solution, we took initial inspiration from Poetiq’s LLM prompts. However, our approach differs significantly from theirs. Poetiq’s solution selects results based on consensus, while our solution uses an evolutionary approach that emphasizes divergence instead of convergence. Our approach also differs fundamentally from other evolutionary approaches such as Jeremy Berman’s 2025 submission in that we use a global population-level sampling approach with a sophisticated per-organism scoring mechanism.
How code evolution can benefit you
We actually developed our Darwinian Evolver tool not to solve ARC-AGI tasks, but to optimize the prompts and decision logic within our agent verifier Vet (Verify Everything). You can download Vet today and reap the benefits of those evolved prompts!
As coding agents and models keep improving, the shape of code quality issues in AI-generated software are going to change as well. We have internally developed tools to automatically generate and annotate high-quality AI code issue data sets on an ongoing basis. Using these data sets, our evolver can automatically distill this ever changing data back down into VET’s internal prompts - thereby giving you better AI-written code and more trustworthy agents.
Of course, this is only one application of evolution-based prompt and code optimization.
We are open-sourcing the underlying Darwinian Evolver tool together with our solution to ARC-AGI. The evolver is problem-agnostic, and can be adapted to virtually any code and/or prompt optimization use case. Please check out the project’s README file for examples and details on how to add your own problem specifications.
To follow along with our builds, subscribe to Imbue’s email newsletter for product updates and events!
Further reading
- Regarding code evolution:
- The darwinian_evolver repository on GitHub. See the README.md to learn how to use our Darwinian Evolver tool for your own optimization needs, or read our separate post to learn about how it works.
- Sakana.ai’s Darwin Gödel Machines and ShinkaEvolve
- Google’s AlphaEvolve - using code evolution for algorithmic discoveries
- Regarding ARC-AGI:
- The ARC-AGI evolver problem implementation used for our results shown in this post
- François Chollet’s 2019 paper On the Measure of Intelligence
- ARC Prize homepage
- Notable other LLM-based ARC-AGI-2 solutions:
- Jeremy Berman’s 2025 submission - another evolution-based approach, evolving natural language rules instead of code
- Poetiq’s ARC-AGI-2 highscore announcement - uses code in conjunction with a consensus-based refinement loop
- Symbolica’s February 10th ARC-AGI-2 SotA - uses an agentic harness and recursive delegation
- Confluence Labs latest highscore - uses Gemini CLI agents with consensus voting
Appendix: Reproduction steps
To reproduce our ARC-AGI-2 results:
- Clone the darwinian_evolver repo and check out commit
1a50d6995e893580c4bd5071725eb24f2317d380(note: Gemini 3 Flash results were obtained using an earlier commit hash482ac638ce46c7f0a166bde25cc5996a15b628b5)
git clone https://github.com/imbue-ai/darwinian_evolver.gitcd darwinian_evolvergit checkout 1a50d6995e893580c4bd5071725eb24f2317d380
- Download the data files for arc-prize-2025 (ARC-AGI-2).
- Obtain an API key for Google Vertex AI, and export the following environment variables:
export GOOGLE_GENAI_USE_VERTEXAI=Trueexport GOOGLE_API_KEY=...
Google AI Studio API keys should also work, but we have not tested those recently. Just skip the GOOGLE_GENAI_USE_VERTEXAI=True export in that case. For Kimi K2.5, we used OpenRouter’s OpenAI compatible API: export OPENAI_API_KEY=...
- For Gemini 3.1 Pro,
export PROVIDER=google. For Gemini 3 Flash,export PROVIDER=google_alt. For Kimi K2.5 via OpenRouter,export PROVIDER=openrouter. - Run
uv run python darwinian_evolver/imbue_experiments/run_arc.py \--challenges arc-prize-2025/arc-agi_evaluation_challenges.json \--solutions arc-prize-2025/arc-agi_evaluation_solutions.json \--hide_solutions \--output_dir arc2-results
The full run will take a few hours and incur a three-digit USD amount in API cost. You can pass --num_problems 25 --shuffle_problems to run on a random 25-problem subset, or pass --help to see other available options.