
Yujia Huang, Caltech: On neuro-inspired generative models
RSS · Spotify · Apple Podcasts · Pocket Casts
Yujia Huang (@YujiaHuangC) is a PhD student at Caltech, working at the intersection of deep learning and neuroscience. She worked on optics and biophotonics before venturing into machine learning. Now, she hopes to design “less artificial” artificial intelligence.
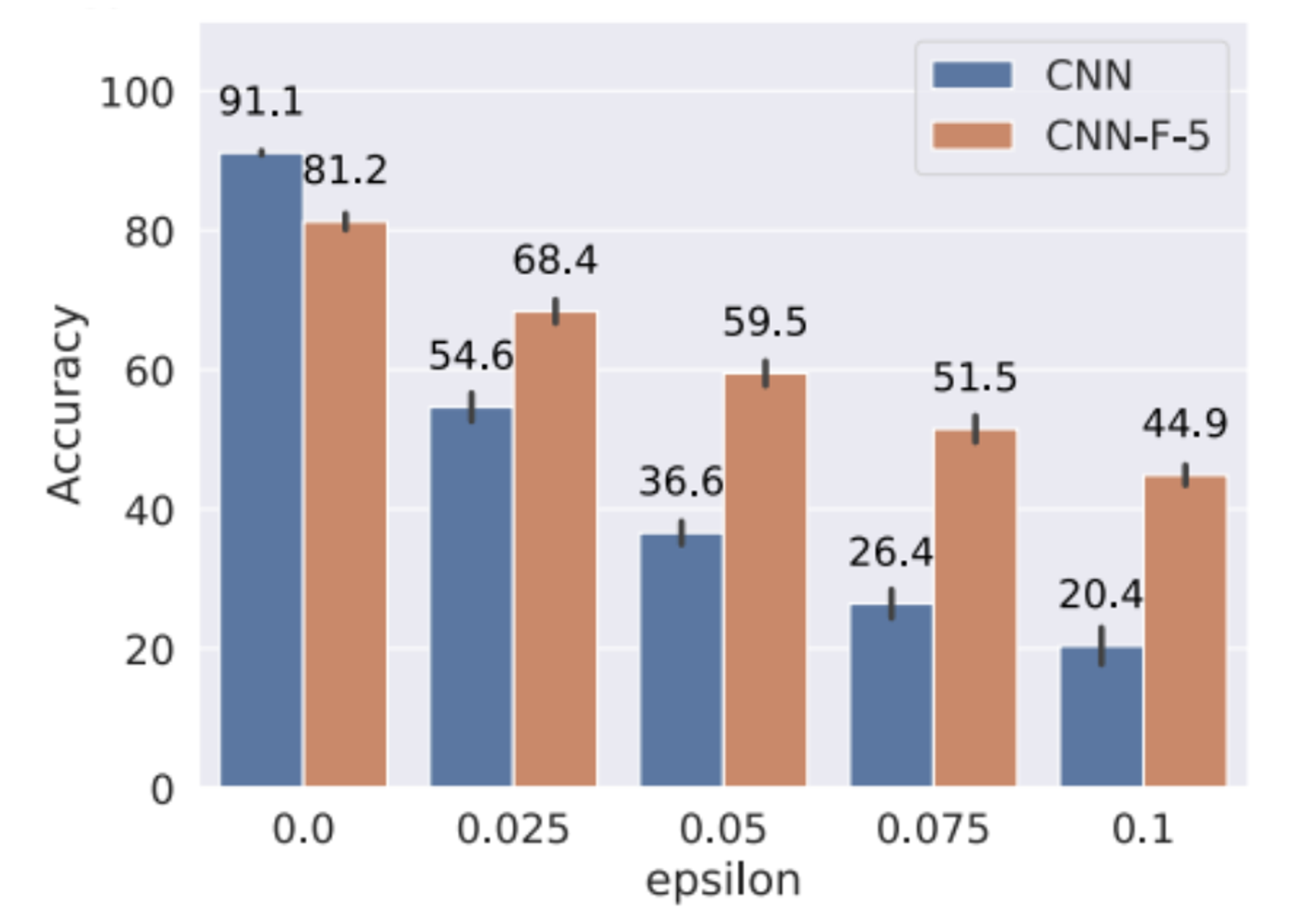
Her most recent paper at NeurIPS is Neural Networks with Recurrent Generative Feedback, introducing Convolutional Neural Networks with Feedback (CNN-F).
Yujia is open to working with collaborators from many areas: neuroscience, signal processing, and control experts — in addition to those interested in generative models for classification. Feel free to reach out to her!
Highlights from our conversation:
🏗 How recurrent generative feedback, a neuro-inspired design, improves adversarial robustness and achieves similar performance with fewer labels
🧠 Drawing inspiration from classical ML & neuroscience for new deep learning models
📊 What a new Turing test for “less artificial” AI could look like
💡 Tips for new machine learning researchers!
Below are the show notes and full transcript. As always, please feel free to reach out with feedback, ideas, and questions!
Some quotes we loved
[04:19] Generative classifiers needing less labels than discriminative ones:
“I got very interested in the idea of using generative models to help classification. It’s actually a pretty old idea, dating back to 2002. Andrew Ng published a paper saying generative classifiers actually can learn more efficiently than discriminative classifiers. You can prove that if you learn using a generative classifier, you need less labels than a discriminative classifier. Intuitively, I think it makes sense because you are trying to get a global sense of the data distribution rather than trying to memorize which Y you should map your X to.”
[06:58] Generative models for classification:
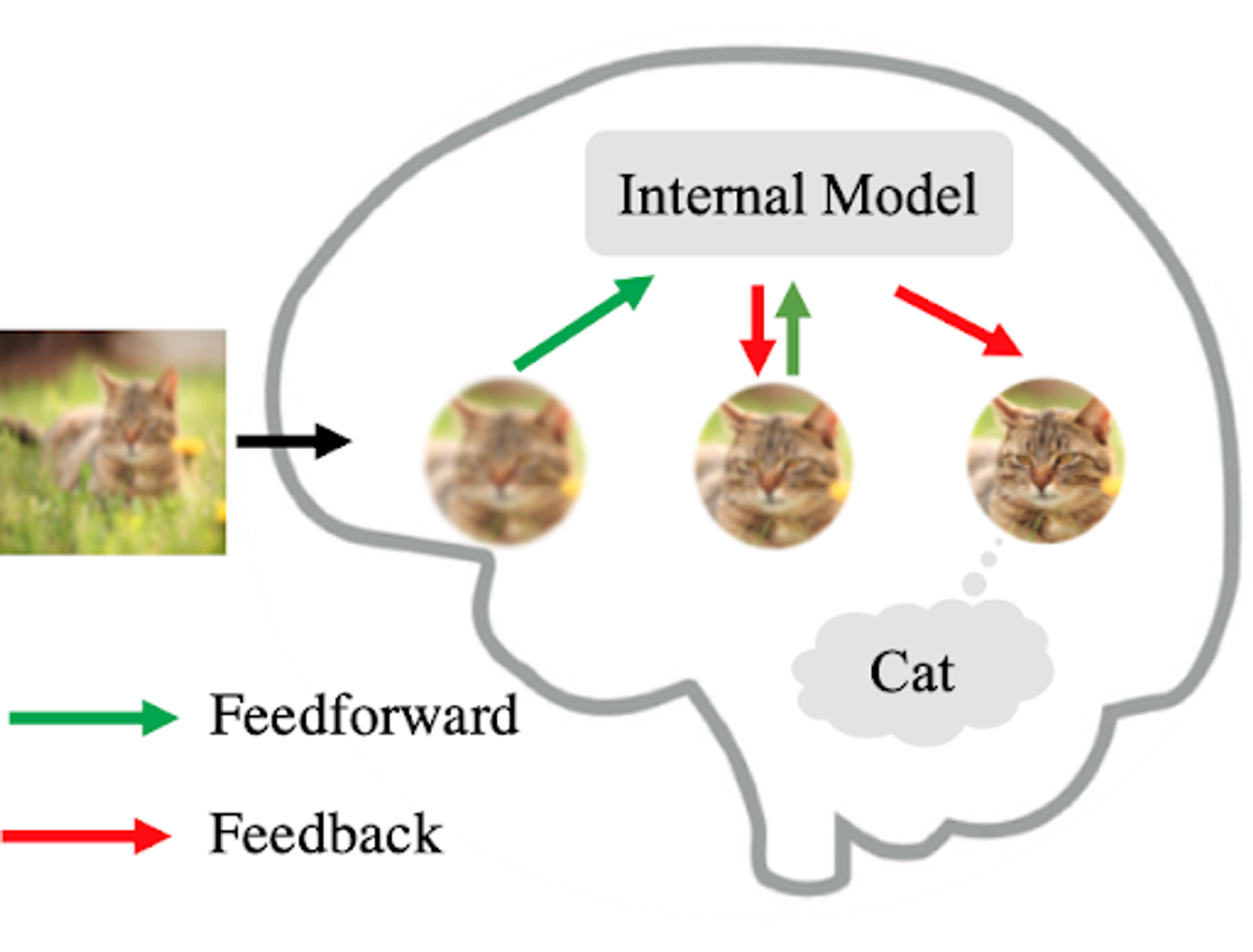
“Why do we need generative models in our classification? I was thinking, if you see a cat, why do you know it’s a cat? It’s because you have the image of a cat in your mind, and you match the external input to the impression or the memory you have in your mind. The memory you have in your mind, or the picture of the cat in your mind could be the result of a generative model. I was thinking of using this sort of generative modeling and this is what I call a recurrent generative feedback in my paper, that could help robustness.”
[28:06] Inspiration from neuroscience and crosstalk between fields:
“I think that people can get inspiration from neuroscience. Look at some classical neuroscience facts or findings, and then formulate it in the language of machine learning to see whether we can get better guarantees using some theoretical tools. And of course, run some experiments to see whether it works or not. After you have this machine learning model, maybe neuroscientists will also take that model to see whether that can provide a better model for neuroscience.”
[30:44] A Turing Test for deep learning models:
“We probably need to have a test for deep learning models, something like a Turing test for deep learning models. One aspect of that test might be the brain score. There could be a lot of other tasks that people can think about.”
[39:38] Training models based on attention:
“To look at different patches of images (during training) - I think that’s very biologically plausible because we do scanning over the visual input ourselves. That attention mechanism is not controversial to what I have developed and these can be combined.”
[54:29] Advice for new researchers - read classical literature:
“I realized people who are very successful in research always find classical stuff and make use of that. I have friends who work on optimization and they proved some theories in stochastic mirror descent and the tools they were using were actually from control theory. That paper dates back to the 1960s or 70s. Try to constantly look back and think, how can I use those tools in my research?”
[56:41] Advice to new researchers - discuss with others:
“It turns out for a lot of ideas, the bingo moment was from discussion with others. It’s faster to learn things via talking with others because they already processed all the data and they are explaining it to you after they’ve seen 20 papers in the same field. For young grad students or researchers, we should have the courage to discuss with people.”
Show Notes
- Yujia on how she came up with her idea for Recurrent Generative Feedback for CNNs [00:00]
- Intro [00:46]
- Yujia’s path to machine learning [1:46]
- Exploring open research problems in school [4:08]
- Generative models for classification [6:58]
- How CNN-Fs and recurrent generative feedback improved upon robustness [8:09]
- Different types of robustness [8:25]
- Anil Seth’s work on consciousness and hallucinations [12:11]
- The origin (theories and previous research) of how Yujia came up with her most recent model [13:55]
- Yujia’s main neuroscience and cognitive science inspirations (James DiCarlo, Josh Tenenbaum, and more) [15:54]
- Biologically plausible generative feedback mechanisms [21:54]
- E-prop vs backprop [22:24]
- How can we properly take inspiration from neuroscience? [22:57]
- How neuroscience and artificial intelligence learn from each other [26:08]
- How does Yujia define “less artificial” artificial intelligence? [29:17]
- A new type of turing test for AI [30:43]
- Making neural networks more intelligent [33:34]
- Disentanglement to help with robustness [34:33]
- Making neural networks smarter during testing [37:19]
- Other inspirations: predictive coding and classical research [41:23]
- Generative models in human brains [47:13]
- CNN-Fs and why they need less labels [48:39]
- Concepts in cognitive science [50:25]
- Recurrent and generative feedback in humans and cognitive science experiments [50:59]
- Tips and tricks for new machine learning researchers [54:14]
- The collaborators Yujia would like to work with [1:02:45]
Thanks to Luke Cheng for writing drafts of this post and Tessa Hall for editing the podcast.