
RSS · Spotify · Apple Podcasts · Pocket Casts
Highlights from our conversation:
🖼 How, surprisingly, the IF-Net architecture learned reasonable representations of humans & objects without priors
🔢 A simple observation that led to Neural Unsigned Distance Fields, which handle 3D scenes without a clear inside vs. outside (most scenes!)
📚 Navigating open questions in 3D representation, and the importance of focusing on what’s working
Below is the full transcript. As always, please feel free to reach out with feedback, ideas, and questions!
Some quotes we loved
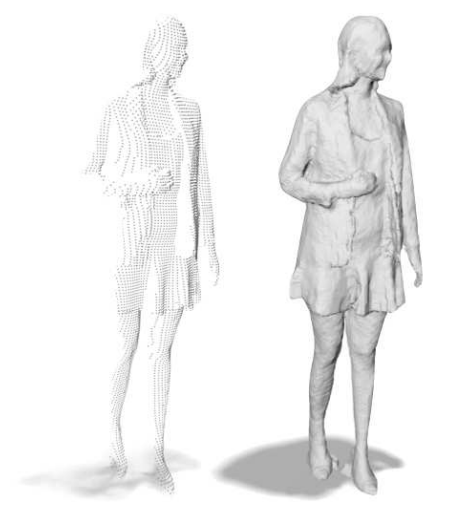
[08:34] What surprised him while working on IF-Nets: How strong neural networks can be! We started with simpler tasks for the paper, but then we started to do some crazy stuff, like just completing the human body where an arm is missing and things like that. The network really does something very reasonable, really learns how a human should look. That was surprising for me actually, that these convolutional layers really do learn something pretty reasonable.
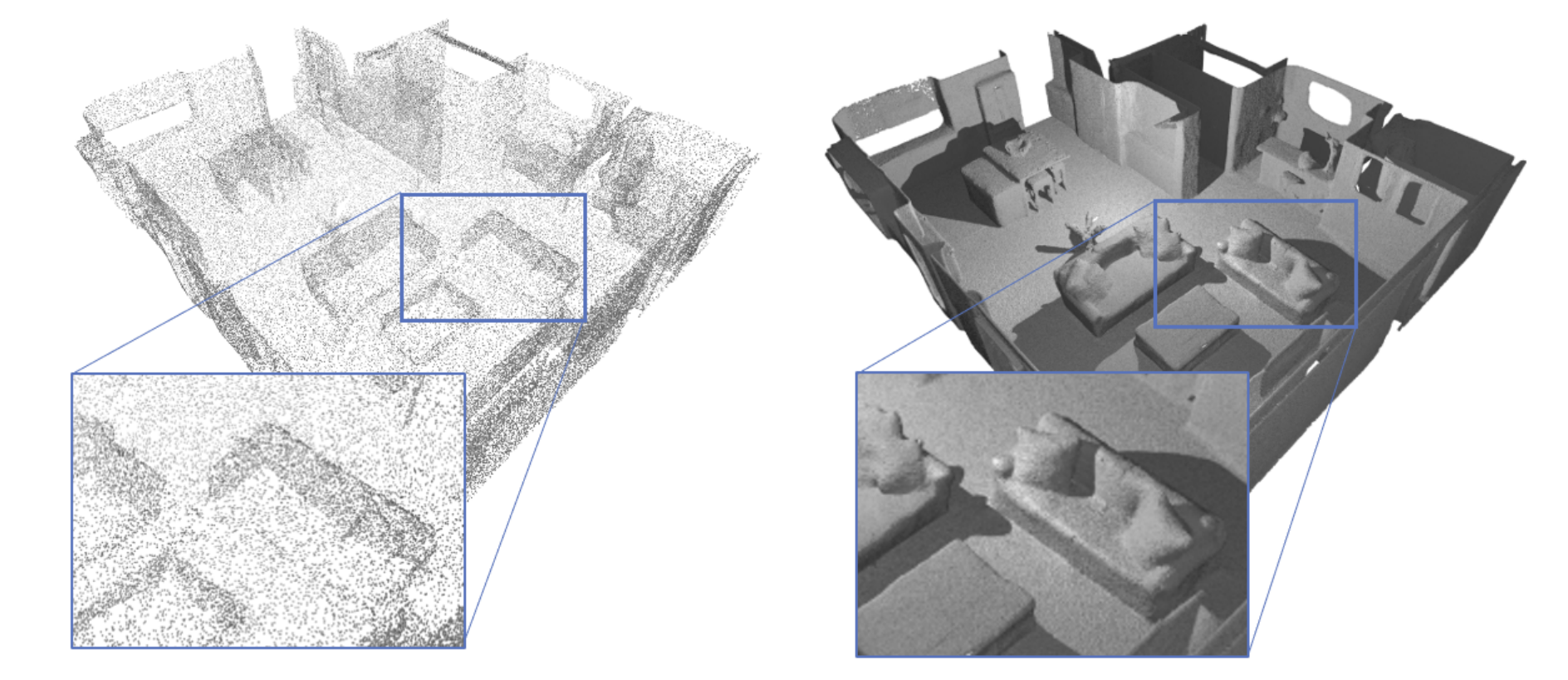
[13:25] Why IF-Nets generated better reconstructions: One very important reason is that we include local information of the inputs, but also encode more global information. If you want to complete the backside of a human, you really need to know where you are relative to the input point cloud, which is maybe only of the front [of the human]. Then you need something very global. The main contribution of the paper is to show how to combine local as well as global information from the input.
[28:42] Why implicit functions have had such an impact: Representing 3D scenes is not so easy as representing a 2D image. For 2D images we know how to represent them: we use grids and for each point in the grid, we have the RGB value stored and that’s it. We all agree that this is a good representation for an image, or at least it’s a very common representation for an image. But it’s different for representing 3D scenes, especially for learning. Mesh is a very dominant representation of 3D surfaces, but it’s not so easy to learn with those when you’re applying a neural network. That was why these implicit [function] papers had such an impact, because this representation wasn’t so clear.
[44:42] Research as a discovery process: Having people who believe in you telling you that what you’re doing is still worthy [is important]. After coming up with these IF-Nets, but having had a different goal, it wasn’t so clear for me after working so much that this is still something useful. But then you have to be reminded again, that if you change the setting, this is really useful for other people or for a different setting. That was also something I’d learn. Many people forget that other stuff is really working well, and instead of pushing what’s working, they try to engineer what’s not working. Sometimes shifting the focus is very helpful. In research, if you already know that everything is working beforehand, then it’s not really research. You have to be open for this discovery process, which is not always as easy as it sounds.
[45:00] On simplicity: I really tend to like small steps in research better than having highly engineered big architectures that solve one task very well, where it’s not really interpretable where this is coming from. I think that’s why NeRF is so popular, because it has a very simple representation. It uses stuff that’s absolutely clear to readers, for example a fully connected network. Also, including volumetric rendering, which is known—they take key things that are known, but do something very important and helpful with it. It’s very clear why it’s working and why it’s not working, instead of sometimes you have papers solving some task but they have four different networks in there, that do not have any real names, they’re just doing something not interpretable.