
Check out our implementation at https://github.com/untitled-ai/slot_attention.
Also, we’re hiring! You can see our open roles, and email us at jobs@imbue.com if you find a role for you.
Why we chose this paper
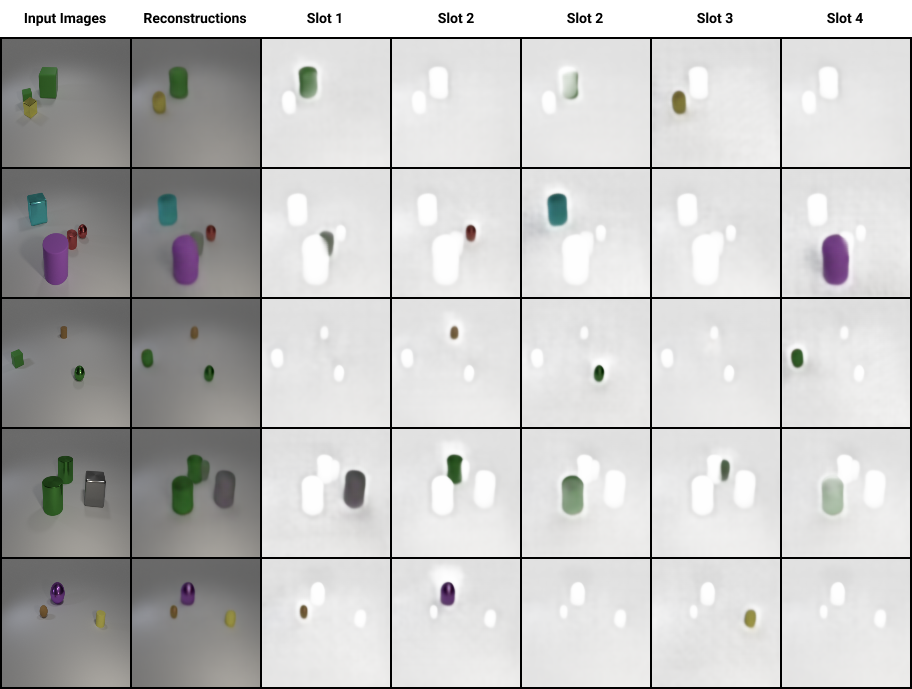
Here’s a question for you, intelligent reader: how many distinct objects do you see in the upper-left image?
This is not a hard question for us humans. However, unsupervised machine learning models have a surprisingly difficult time answering this: they struggle to understand which pixels constitute an object by human standards. And while there’s been success in training supervised models to complete this task 1, it’s largely unsolved on the unsupervised side 2.
You can see the issue here. It’s important that machines actually understand what objects are, because countless elementary tasks that humans can do require this basic capability.
Enter Object-Centric Learning with Slot Attention. This nifty technique introduces a novel way to extract objects from the original input without any training or supervision. After an image is processed (for example, through a CNN) into feature representations, a Slot Attention module forces “slots” to compete over these features, using an iterative attention mechanism similar to the attention mechanism popular in other domains of machine learning 3. At each iteration, slots compete to explain parts of input features, and then update their representation.
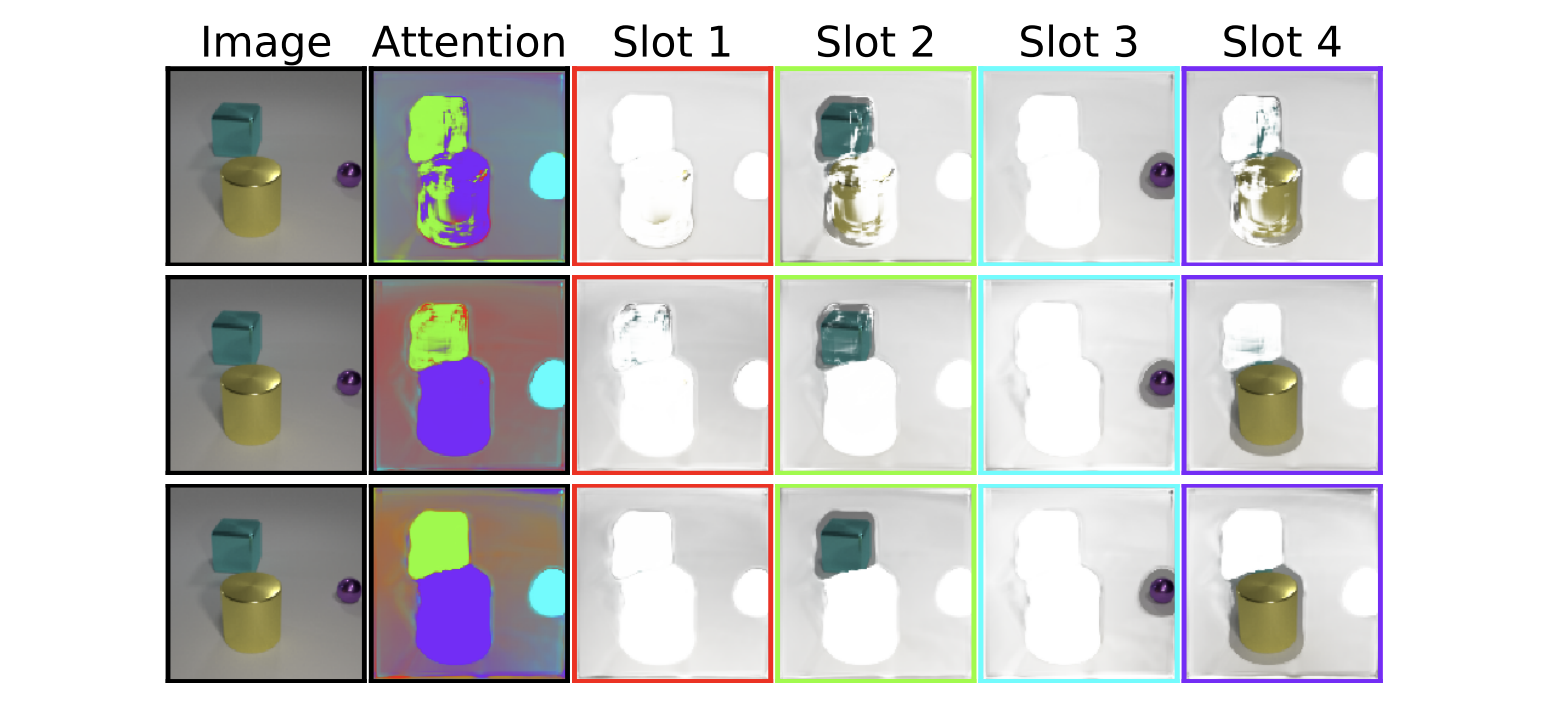
It’s exciting that unsupervised models can now determine objects from complex scenes, and can even do so without using depth, motion, or other helpful signals.
What’s next?
While slot attention is a step in the right direction toward unsupervised object understanding, there are plenty of interesting open questions:
- How can this work on real data with many objects and noisy backgrounds?
- Our team works heavily with video and objects in motion. How well would it work if we determined objects in an image based on what they’re doing - for example, whether they’re moving, or static?
- Instead of reconstruction loss, what would happen if we use a contrastive loss instead? (See this related work by Sindy Löwe)
By reimplementing this paper and sharing our code, we hope we can allow others to help answer these questions, and more.
Note: We did not fully reproduce the result of the paper due to time and GPU constraints, so drop a ticket on our Github page if you have any issues. If you have thoughts on the model, where you think it’d be useful, etc., please shoot us a note at josh@imbue.com. We’re happy to chat!
Sources
-
Object-Centric Learning with Slot Attention, https://arxiv.org/abs/2006.15055.
-
Slot Attention in Tensorflow, https://github.com/google-research/google-research/tree/master/slot_attention.
References
-
A similar supervised approach to this problem is semantic segmentation. This task involves grouping pixels of an image together that belong to the same object or entity. This means every pixel in the image is labelled with a class that corresponds to a specific object. See more here. ↩
-
Getting labelled data is expensive and time consuming. We also believe that in order for a model to truly generalize it will need more labelled data than we can produce. Unsupervised learning would circumvent this need. ↩
-
This attention mechanism mentioned here was introduced in Attention Is All You Need. ↩